Orchestrate Snowflake Queries with Airflow
Snowflake is one of the most commonly used data warehouses, and orchestrating Snowflake queries as part of a data pipeline is one of the most common Airflow use cases. Two Airflow provider packages, the Snowflake Airflow provider and the Common SQL provider contain hooks and operators that make it easy to interact with Snowflake from Airflow.
This tutorial covers an example of executing Snowflake operations with Airflow, including:
- Setting up a connection to Snowflake in Airflow.
- Executing individual SQL statements using the SQLExecuteQueryOperator.
- Executing multiple SQL statements using the SnowflakeSqlApiOperator.
- Running data quality checks using the SQLColumnCheckOperator.
Additionally, More on the Airflow Snowflake integration offers further information on general best practices and considerations when interacting with Snowflake from Airflow.
There are multiple resources for learning about this topic. See also:
- Reference architecture: ELT with Snowflake and Apache Airflow® for eCommerce, a complete end-to-end ELT pipeline with Snowflake and Airflow, including usage of the CopyFromExternalStageToSnowflakeOperator.
- Reference architecture: Introducing SnowPatrol - Snowflake Anomaly Detection and Cost Management with Machine Learning and Airflow, learn how you can use Airflow to improve your Snowflake cost management.
- Webinar: Implementing reliable ETL & ELT pipelines with Airflow and Snowflake.
- Tutorial: Orchestrate Snowpark Machine Learning Workflows with Apache Airflow, a tutorial on how to use the experimental Snowpark Airflow provider.
- See how Snowflake pipelines can run on Astro.
Time to complete
This tutorial takes approximately 20 minutes to complete.
Assumed knowledge
To get the most out of this tutorial, make sure you have an understanding of:
- Snowflake basics. See Introduction to Snowflake.
- Airflow operators. See Airflow operators.
- SQL basics. See the W3 SQL tutorial.
Prerequisites
- The Astro CLI.
- A Snowflake account. A 30-day free trial is available. You need to have at least one database, one schema and one warehouse set up in your Snowflake account as well as a user with the necessary permissions to create tables and run queries in the schema.
Step 1: Configure your Astro project
Use the Astro CLI to create and run an Airflow project on your local machine.
-
Create a new Astro project:
$ mkdir astro-snowflake-tutorial && cd astro-snowflake-tutorial
$ astro dev init -
In the
requirements.txtfile, add the Snowflake Airflow provider and the Common SQL provider.apache-airflow-providers-snowflake==5.7.0
apache-airflow-providers-common-sql==1.16.0 -
Run the following command to start your Airflow project:
astro dev start
Step 2: Configure a Snowflake connection
There are different options to authenticate to Snowflake. The SnowflakeAPIOperator used in this tutorial requires you to use key-pair authentication, which is the preferred method. This method requires you to generate a public/private key pair, add the public key to your role in Snowflake, and use the private key in your Airflow connection.
For Astro customers, Astronomer recommends to take advantage of the Astro Environment Manager to store connections in an Astro-managed secrets backend. These connections can be shared across multiple deployed and local Airflow environments. See Manage Astro connections in branch-based deploy workflows. Note that when using the Astro Environment Manager for your Snowflake connection, you can directly paste the private key into the Private Key Content field in the UI without needing to modify it.
-
In your terminal, run the following command to generate a private RSA key using OpenSSL. Note that while there are other options to generate a key pair, Snowflake has specific requirements for the key format and may not accept keys generated with other tools. Make sure to write down the key passphrase as you will need it later.
openssl genrsa 2048 | openssl pkcs8 -topk8 -inform PEM -out rsa_key.p8 -
Generate the associated public key using the following command:
openssl rsa -in rsa_key.p8 -pubout -out rsa_key.pub -
In the Snowflake UI, run the following SQL command to add the public key to your user. You can paste the public key directly from the
rsa_key.pubfile without needing to modify it.ALTER USER <your user> SET RSA_PUBLIC_KEY='<your public key>'; -
In the Airflow UI, go to Admin -> Connections and click + to create a new connection. Choose the
Snowflakeconnection type and enter the following information:-
Connection ID:
snowflake_conn -
Schema: Your Snowflake schema. The example DAG uses
DEMO_SCHEMA. -
Login: Your Snowflake user name. Make sure to capitalize the user name as the SnowflakeAPIOperator requires it.
-
Password: Your private key passphrase.
-
Extra: Enter the following JSON object with your own Snowflake account identifier, database, your role in properly capitalized format, and your warehouse.
{
"account": "<your account id in the form of abc12345>",
"warehouse": "<your warehouse>",
"database": "DEMO_DB",
"region": "<your region>",
"role": "<your role in capitalized format>",
"private_key_content": "-----BEGIN ENCRYPTED PRIVATE KEY-----\nABC...ABC\nABC...ABC=\n-----END ENCRYPTED PRIVATE KEY-----\n"
}For the
private_key_contentfield, paste the contents of thersa_key.p8file. Make sure to replace newlines with\n. You can use the script below to format the key correctly:def format_private_key(private_key_path):
with open(private_key_path, 'r') as key_file:
private_key = key_file.read()
return private_key.replace('\n', '\\n')
formatted_key = format_private_key('rsa_key.pem')
print(formatted_key)
Your connection should look something like the screenshot below.
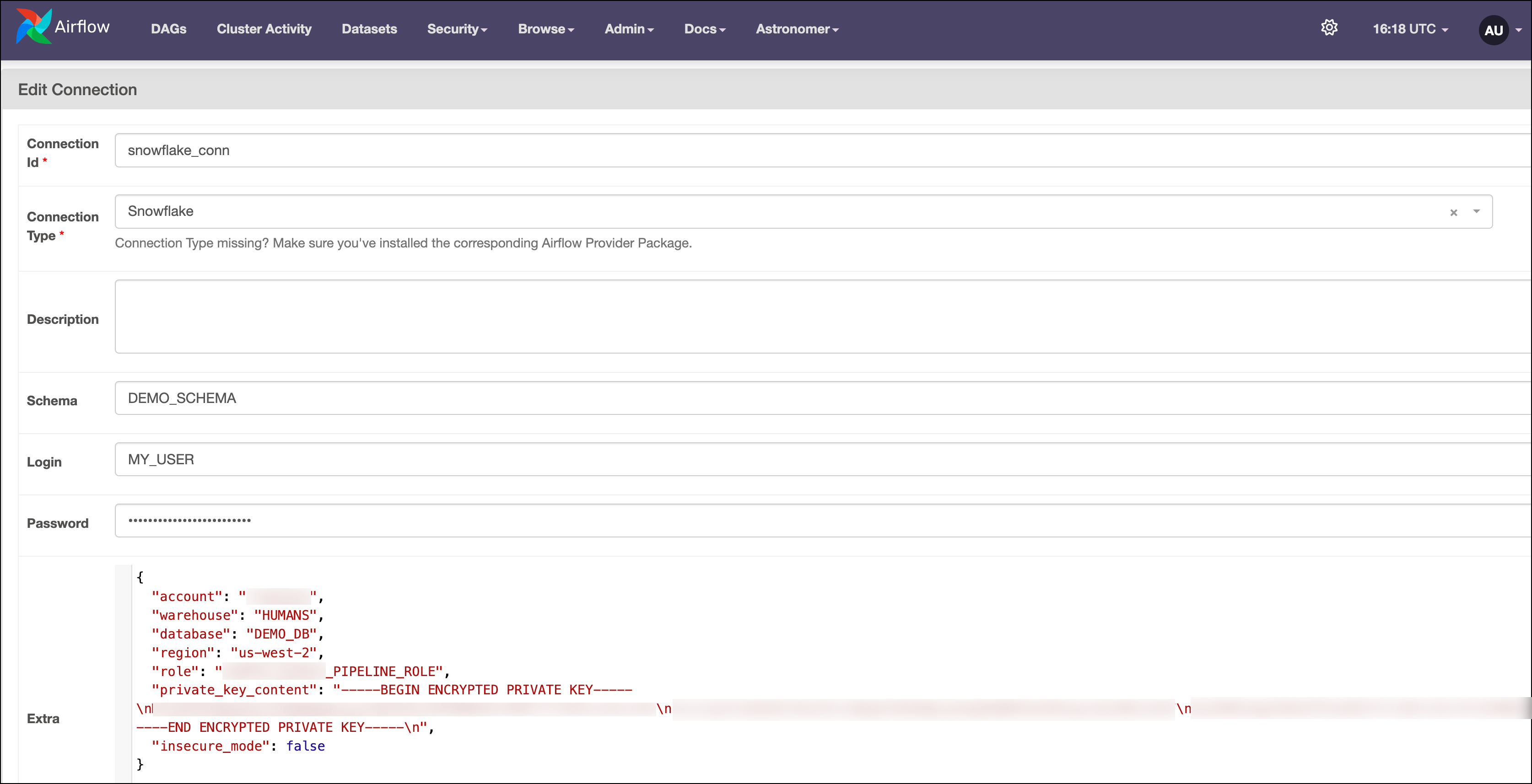
-
When using JSON format to set your connection use the following parameters:
AIRFLOW_CONN_SNOWFLAKE_DEFAULT='{
"conn_type":"snowflake",
"login":"<your user, properly capitalized>",
"password":"<your private key passphrase>",
"schema":"DEMO_SCHEMA",
"extra":{
"account":"<your account id in the form of abc12345",
"warehouse":"<your warehouse>",
"database":"DEMO_DB",
"region":"<your region>",
"role":"<your role, properly capitalized>",
"private_key_content":"-----BEGIN ENCRYPTED PRIVATE KEY-----\nABC...ABC\nABC...ABC=\n-----END ENCRYPTED PRIVATE KEY-----\n"
}'
Step 3: Add your SQL statements
The DAG you will create in Step 4 runs multiple SQL statements against your Snowflake data warehouse. While it is possible to add SQL statements directly in your DAG file it is common practice to store them in separate files. When initializing your Astro project with the Astro CLI, an include folder was created. The contents of this folder will automatically be mounted into the Dockerfile, which makes it the standard location in which supporting files are stored.
-
Create a folder called
sqlin yourincludefolder. -
Create a new file in
include/sqlcalledinsert_data.sqland copy the following code:INSERT INTO {{ params.db_name }}.{{ params.schema_name }}.{{ params.table_name }} (ID, NAME)
VALUES
(1, 'Avery');This file contains one SQL statement that inserts a row into a table. The database, schema and table names are parameterized so that you can pass them to the operator at runtime.
-
The SnowflakeSqlApiOperator can run multiple SQL statements in a single task. Create a new file in
include/sqlcalledmultiple_statements_query.sqland copy the following code:INSERT INTO {{ params.db_name }}.{{ params.schema_name }}.{{ params.table_name }} (ID, NAME)
VALUES
(2, 'Peanut'),
(3, 'Butter');
INSERT INTO {{ params.db_name }}.{{ params.schema_name }}.{{ params.table_name }} (ID, NAME)
VALUES
(4, 'Vega'),
(5, 'Harper');This file contains two SQL statements that insert multiple rows into a table.
When running SQL statements from Airflow operators, you can store the SQL code in individual SQL files, in a combined SQL file, or as strings in a Python module. Astronomer recommends storing lengthy SQL statements in a dedicated file to keep your DAG files clean and readable.
Step 4: Write a Snowflake DAG
-
Create a new file in your
dagsdirectory calledmy_snowflake_dag.py. -
Copy and paste the code below into the file:
"""
### Snowflake Tutorial DAG
This DAG demonstrates how to use the SQLExecuteQueryOperator,
SnowflakeSqlApiOperator and SQLColumnCheckOperator to interact with Snowflake.
"""
from airflow.decorators import dag
from airflow.providers.common.sql.operators.sql import SQLExecuteQueryOperator
from airflow.providers.common.sql.operators.sql import SQLColumnCheckOperator
from airflow.providers.snowflake.operators.snowflake import SnowflakeSqlApiOperator
from airflow.models.baseoperator import chain
from pendulum import datetime, duration
import os
_SNOWFLAKE_CONN_ID = "snowflake_conn"
_SNOWFLAKE_DB = "DEMO_DB"
_SNOWFLAKE_SCHEMA = "DEMO_SCHEMA"
_SNOWFLAKE_TABLE = "DEMO_TABLE"
@dag(
dag_display_name="Snowflake Tutorial DAG ❄️",
start_date=datetime(2024, 9, 1),
schedule=None,
catchup=False,
default_args={"owner": "airflow", "retries": 1, "retry_delay": duration(seconds=5)},
doc_md=__doc__,
tags=["tutorial"],
template_searchpath=[
os.path.join(os.path.dirname(os.path.abspath(__file__)), "../include/sql")
], # path to the SQL templates
)
def my_snowflake_dag():
# you can execute SQL queries directly using the SQLExecuteQueryOperator
create_or_replace_table = SQLExecuteQueryOperator(
task_id="create_or_replace_table",
conn_id=_SNOWFLAKE_CONN_ID,
database="DEMO_DB",
sql=f"""
CREATE OR REPLACE TABLE {_SNOWFLAKE_SCHEMA}.{_SNOWFLAKE_TABLE} (
ID INT,
NAME VARCHAR
)
""",
)
# you can also execute SQL queries from a file, make sure to add the path to the template_searchpath
insert_data = SQLExecuteQueryOperator(
task_id="insert_data",
conn_id=_SNOWFLAKE_CONN_ID,
database="DEMO_DB",
sql="insert_data.sql",
params={
"db_name": _SNOWFLAKE_DB,
"schema_name": _SNOWFLAKE_SCHEMA,
"table_name": _SNOWFLAKE_TABLE,
},
)
# you can also execute multiple SQL statements using the SnowflakeSqlApiOperator
# make sure to set the statement_count parameter to the number of statements in the SQL file
# and that your connection details are in their proper capitalized form!
insert_data_multiple_statements = SnowflakeSqlApiOperator(
task_id="insert_data_multiple_statements",
snowflake_conn_id=_SNOWFLAKE_CONN_ID,
sql="multiple_statements_query.sql",
database=_SNOWFLAKE_DB,
schema=_SNOWFLAKE_SCHEMA,
params={
"db_name": _SNOWFLAKE_DB,
"schema_name": _SNOWFLAKE_SCHEMA,
"table_name": _SNOWFLAKE_TABLE,
},
statement_count=2, # needs to match the number of statements in the SQL file
autocommit=True,
)
# use SQLCheck operators to check the quality of your data
data_quality_check = SQLColumnCheckOperator(
task_id="data_quality_check",
conn_id=_SNOWFLAKE_CONN_ID,
database=_SNOWFLAKE_DB,
table=f"{_SNOWFLAKE_SCHEMA}.{_SNOWFLAKE_TABLE}",
column_mapping={
"ID": {"null_check": {"equal_to": 0}, "distinct_check": {"geq_to": 3}}
},
)
chain(
create_or_replace_table,
insert_data,
insert_data_multiple_statements,
data_quality_check,
)
my_snowflake_dag()The DAG completes the following steps:
- Uses the SQLExecuteQueryOperator to run an in-line SQL statement that creates a table in Snowflake.
- Uses the SQLExecuteQueryOperator to run an SQL file containing a singular SQL statement that inserts data into the table.
- Uses the SnowflakeSqlApiOperator to run an SQL file containing multiple SQL statements that insert data into the table. The operator is set to run in deferrable mode.
- Uses the SQLColumnCheckOperator to run a data quality check on the table checking that there are no NULL values in the
IDcolumn and that it contains at least 3 distinct values. To learn more about SQL check operators, see Run data quality checks using SQL check operators.
The
chain()method at the end of the DAG sets the dependencies. This method is commonly used over bitshift operators (>>) to make it easier to read dependencies between many tasks.
Step 5: Run the DAG
-
In the Airflow UI, click the play button to manually run your DAG.
-
Open the logs for the
data_quality_checktask to see the results of the data quality check, confirming that the table was created and populated correctly.[2024-09-12, 16:03:09 UTC] {sql.py:469} INFO - Record: [('ID', 'null_check', 0), ('ID', 'distinct_check', 5)]
[2024-09-12, 16:03:09 UTC] {sql.py:492} INFO - All tests have passed
More on the Airflow Snowflake integration
This section provides additional information on orchestrating actions in Snowflake with Airflow.
Snowflake Operators and Hooks
Several open source packages contain operators used to orchestrate Snowflake in Airflow.
The Common SQL provider package contains operators that you can use with several SQL databases, including Snowflake:
- SQLExecuteQueryOperator: Executes a single SQL statement. This operator replaces the deprecated
SnowflakeOperator. - SQLColumnCheckOperator: Performs a data quality check against columns of a given table. See Run data quality checks using SQL check operators.
- SQLTableCheckOperator: Performs a data quality check against a given table.
The Snowflake provider package contains:
- SnowflakeSqlApiOperator: Executes multiple SQL statements in a single task. Note that this operator uses the Snowflake SQL API, which requires connection parameters such as the role and user to be properly capitalized. The operator can be set to be deferrable using
deferrable=True. - CopyFromExternalStageToSnowflakeOperator: Copies data from an external stage to a Snowflake table. Note that the
prefixparameter will be added to the full stage path defined in Snowflake. See the ELT with Snowflake and Apache Airflow® for eCommerce reference architecture for an example of how to use this operator. - SnowflakeHook: A client to interact with Snowflake which is commonly used when building custom operators interacting with Snowflake.
Best practices and considerations
The following are some best practices and considerations to keep in mind when orchestrating Snowflake queries from Airflow:
- To reduce costs and improve the scalability of your Airflow environment, consider using the SnowflakeSqlApiOperator in deferrable mode for long running queries.
- Set your default Snowflake query specifications such as Warehouse, Role, Schema, and so on in the Airflow connection. Then overwrite those parameters for specific tasks as necessary in your operator definitions. This is cleaner and easier to read than adding
USE Warehouse XYZ;statements within your queries. If you are an Astro customer, use the Astro Environment Manager to define your base connection and add overrides for specific deployments and tasks. - Pay attention to which Snowflake compute resources your tasks are using, as overtaxing your assigned resources can cause slowdowns in your Airflow tasks. It is generally recommended to have different warehouses devoted to your different Airflow environments to ensure DAG development and testing does not interfere with DAGs running in production. If you want to optimize your Snowflake usage, consider using SnowPatrol to detect anomalies in your Snowflake spend.
- Make use of Snowflake stages together with the CopyFromExternalStageToSnowflakeOperator when loading large amounts data from an external system using Airflow. To see how to use this operator, check out the ELT with Snowflake and Apache Airflow® for eCommerce reference architecture.
Conclusion
Congratulations! You've connected Airflow to Snowflake and executed Snowflake queries from your Airflow DAGs. You've also learned about best practices and considerations when orchestrating Snowflake queries from Airflow.