Orchestrate Snowpark Machine Learning Workflows with Apache Airflow
Snowpark is the set of runtimes and libraries that securely deploy and process Python and other programming code in Snowflake. This includes Snowpark ML, the Python library and underlying infrastructure for end-to-end ML workflows in Snowflake. Snowpark ML has 2 components: Snowpark ML Modeling for model development, and Snowpark ML Operations including the Snowpark Model Registry, for model deployment and management.
In this tutorial, you'll learn how to:
- Create a custom XCom backend in Snowflake.
- Create and use the Snowpark Model Registry in Snowflake.
- Use Airflow decorators to run code in Snowpark, both in a pre-built and custom virtual environment.
- Run a Logistic Regression model on a synthetic dataset to predict skiers' afternoon beverage choice.
The provider used in this tutorial is currently in beta and both its contents and decorators are subject to change. After the official release, this tutorial will be updated.
Why use Airflow with Snowpark?
Snowpark allows you to use Python to perform transformations and machine learning operations on data stored in Snowflake.
Integrating Snowpark for Python with Airflow offers the benefits of:
- Running machine learning models directly in Snowflake, without having to move data out of Snowflake.
- Expressing data transformations in Snowflake in Python instead of SQL.
- Storing and versioning your machine learning models using the Snowpark Model Registry inside Snowflake.
- Using Snowpark's compute resources instead of your Airflow cluster resources for machine learning.
- Using Airflow for Snowpark Python orchestration to enable automation, auditing, logging, retry, and complex triggering for powerful workflows.
The Snowpark provider for Airflow simplifies interacting with Snowpark by:
- Connecting to Snowflake using an Airflow connection, removing the need to directly pass credentials in your DAG.
- Automatically instantiating a Snowpark session.
- Automatically serializing and deserializing Snowpark dataframes passed using Airflow XCom.
- Integrating with OpenLineage.
- Providing a pre-built custom XCom backend for Snowflake.
Additionally, this tutorial shows how to use Snowflake as a custom XCom backend. This is especially useful for organizations with strict compliance requirements who want to keep all their data in Snowflake, but still leverage Airflow XCom to pass data between tasks.
Time to complete
This tutorial takes approximately 45 minutes to complete.
Assumed knowledge
To get the most out of this tutorial, make sure you have an understanding of:
- The basics of Snowflake and Snowpark. See Introduction to Snowflake and the Snowpark API documentation.
- Airflow decorators. See Introduction to the TaskFlow API and Airflow decorators.
- Airflow connections. See Managing your Connections in Apache Airflow.
- Setup/ teardown tasks in Airflow. See Use setup and teardown tasks in Airflow.
Prerequisites
-
The Astro CLI.
-
A Snowflake account. A 30-day free trial is available. You need to have at least one database and one schema created to store the data and models used in this tutorial.
-
(Optional) This tutorial includes instructions on how to use the Snowflake custom XCom backend included in the provider. If you want to this custom XCom backend you will need to either:
-
Run the DAG using a Snowflake account with
ACCOUNTADMINprivileges to allow the DAG's first task to create the required database, schema, stage and table. See Step 3.3 for more instructions. The free trial account has the required privileges. -
Ask your Snowflake administrator to:
- Provide you with the name of an existing database, schema, and stage. You need to use these names in Step 1.8 for the
AIRFLOW__CORE__XCOM_SNOWFLAKE_TABLEandAIRFLOW__CORE__XCOM_SNOWFLAKE_STAGEenvironment variables. - Create an
XCOM_TABLEwith the following schema:
dag_id varchar NOT NULL,
task_id varchar NOT NULL,
run_id varchar NOT NULL,
multi_index integer NOT NULL,
key varchar NOT NULL,
value_type varchar NOT NULL,
value varchar NOT NULL - Provide you with the name of an existing database, schema, and stage. You need to use these names in Step 1.8 for the
-
The example code from this tutorial is also available on GitHub.
Step 1: Configure your Astro project
-
Create a new Astro project:
$ mkdir astro-snowpark-tutorial && cd astro-snowpark-tutorial
$ astro dev init -
Create a new file in your Astro project's root directory called
requirements-snowpark.txt. This file contains all Python packages that you install in your reuseable Snowpark environment.psycopg2-binary
snowflake_snowpark_python[pandas]>=1.11.1
git+https://github.com/astronomer/astro-provider-snowflake.git
virtualenv -
Change the content of the
Dockerfileof your Astro project to the following, which creates a virtual environment by using the Astro venv buildkit. The requirements added in the previous step are installed in that virtual environment. This tutorial includes Snowpark Python tasks that are running in virtual environments, which is a common pattern in production to simplify dependency management. This Dockerfile creates a virtual environment calledsnowparkwith the Python version 3.8 and the packages specified inrequirements-snowpark.txt.# syntax=quay.io/astronomer/airflow-extensions:latest
FROM quay.io/astronomer/astro-runtime:10.2.0
# Create the virtual environment
PYENV 3.8 snowpark requirements-snowpark.txt
# Install packages into the virtual environment
COPY requirements-snowpark.txt /tmp
RUN python3.8 -m pip install -r /tmp/requirements-snowpark.txt -
Add the following package to your
packages.txtfile:build-essential
git -
Add the following packages to your
requirements.txtfile. The Astro Snowflake provider is installed from thewhlfile.apache-airflow-providers-snowflake==5.2.0
apache-airflow-providers-amazon==8.15.0
snowflake-snowpark-python[pandas]==1.11.1
snowflake-ml-python==1.1.2
matplotlib==3.8.1
git+https://github.com/astronomer/astro-provider-snowflake.git
The Astro Snowflake provider is currently in beta. Classes from this provider might be subject to change and will be included in the Snowflake provider in a future release.
-
To create an Airflow connection to Snowflake and allow serialization of Astro Python SDK objects, add the following to your
.envfile. Make sure to enter your own Snowflake credentials as well as the name of an existing database and schema.AIRFLOW__CORE__ALLOWED_DESERIALIZATION_CLASSES=airflow\.* astro\.*
AIRFLOW_CONN_SNOWFLAKE_DEFAULT='{
"conn_type":"snowflake",
"login":"<username>",
"password":"<password>",
"schema":"MY_SKI_DATA_SCHEMA",
"extra":
{
"account":"<account>",
"warehouse":"<warehouse>",
"database":"MY_SKI_DATA_DATABASE",
"region":"<region>",
"role":"<role>",
"authenticator":"snowflake",
"session_parameters":null,
"application":"AIRFLOW"
}
}'
For more information on creating a Snowflake connection, see Create a Snowflake connection in Airflow.
-
(Optional) If you want to use a Snowflake custom XCom backend, add the following additional variables to your
.env. Replace the values with the name of your own database, schema, table, and stage if you are not using the suggested values.AIRFLOW__CORE__XCOM_BACKEND=snowpark_provider.xcom_backends.snowflake.SnowflakeXComBackend
AIRFLOW__CORE__XCOM_SNOWFLAKE_TABLE='AIRFLOW_XCOM_DB.AIRFLOW_XCOM_SCHEMA.XCOM_TABLE'
AIRFLOW__CORE__XCOM_SNOWFLAKE_STAGE='AIRFLOW_XCOM_DB.AIRFLOW_XCOM_SCHEMA.XCOM_STAGE'
AIRFLOW__CORE__XCOM_SNOWFLAKE_CONN_NAME='snowflake_default'
Step 2: Add your data
The DAG in this tutorial runs a classification model on synthetic data to predict which afternoon beverage a skier will choose based on attributes like ski color, ski resort, and amount of new snow. The data is generated using this script.
-
Create a new directory in your Astro project's
includedirectory calleddata. -
Download the dataset from Astronomer's GitHub and save it in
include/data.
Step 3: Create your DAG
-
In your
dagsfolder, create a file calledairflow_with_snowpark_tutorial.py. -
Copy the following code into the file. Make sure to provide your Snowflake database and schema names to
MY_SNOWFLAKE_DATABASEandMY_SNOWFLAKE_SCHEMA."""
### Orchestrate data transformation and model training in Snowflake using Snowpark
This DAG shows how to use specialized decorators to run Snowpark code in Airflow.
Note that it uses the Airflow 2.7 feature of setup/ teardown tasks to create
and clean up a Snowflake custom XCom backend.
If you want to use regular XCom set
`SETUP_TEARDOWN_SNOWFLAKE_CUSTOM_XCOM_BACKEND` to `False`.
"""
from datetime import datetime
from airflow.decorators import dag, task
from astro import sql as aql
from astro.files import File
from astro.sql.table import Table
from airflow.models.baseoperator import chain
# toggle to True if you are using the Snowflake XCOM backend and want to
# use setup/ teardown tasks to create all necessary objects and clean up the XCOM table
# after the DAG has run
SETUP_TEARDOWN_SNOWFLAKE_CUSTOM_XCOM_BACKEND = False
# provide your Snowflake XCOM database, schema, stage and table names
MY_SNOWFLAKE_XCOM_DATABASE = "SNOWPARK_XCOM_DB"
MY_SNOWFLAKE_XCOM_SCHEMA = "SNOWPARK_XCOM_SCHEMA"
MY_SNOWFLAKE_XCOM_STAGE = "XCOM_STAGE"
MY_SNOWFLAKE_XCOM_TABLE = "XCOM_TABLE"
# provide your Snowflake database name, schema name, connection ID
# and path to the Snowpark environment binary
MY_SNOWFLAKE_DATABASE = "MY_SKI_DATA_DATABASE" # an existing database
MY_SNOWFLAKE_SCHEMA = "MY_SKI_DATA_SCHEMA" # an existing schema
MY_SNOWFLAKE_TABLE = "MY_SKI_DATA_TABLE"
SNOWFLAKE_CONN_ID = "snowflake_default"
SNOWPARK_BIN = "/home/astro/.venv/snowpark/bin/python"
# while this tutorial will run with the default Snowflake warehouse, larger
# datasets may require a Snowpark optimized warehouse. Set the following toggle to true to
# use such a warehouse and provide your Snowpark and regular warehouses' names.
USE_SNOWPARK_WAREHOUSE = False
MY_SNOWPARK_WAREHOUSE = "SNOWPARK_WH"
MY_SNOWFLAKE_REGULAR_WAREHOUSE = "HUMANS"
@dag(
start_date=datetime(2023, 9, 1),
schedule=None,
catchup=False,
)
def airflow_with_snowpark_tutorial():
if SETUP_TEARDOWN_SNOWFLAKE_CUSTOM_XCOM_BACKEND:
@task.snowpark_python(
snowflake_conn_id=SNOWFLAKE_CONN_ID,
)
def create_snowflake_objects(
snowflake_xcom_database,
snowflake_xcom_schema,
snowflake_xcom_table,
snowflake_xcom_table_stage,
use_snowpark_warehouse=False,
snowpark_warehouse=None,
):
from snowflake.snowpark.exceptions import SnowparkSQLException
try:
snowpark_session.sql(
f"""CREATE DATABASE IF NOT EXISTS
{snowflake_xcom_database};
"""
).collect()
print(f"Created database {snowflake_xcom_database}.")
snowpark_session.sql(
f"""CREATE SCHEMA IF NOT EXISTS
{snowflake_xcom_database}.
{snowflake_xcom_schema};
"""
).collect()
print(f"Created schema {snowflake_xcom_schema}.")
if use_snowpark_warehouse:
snowpark_session.sql(
f"""CREATE WAREHOUSE IF NOT EXISTS
{snowpark_warehouse}
WITH
WAREHOUSE_SIZE = 'MEDIUM'
WAREHOUSE_TYPE = 'SNOWPARK-OPTIMIZED';
"""
).collect()
print(f"Created warehouse {snowpark_warehouse}.")
except SnowparkSQLException as e:
print(e)
print(
f"""You do not have the necessary privileges to create objects in Snowflake.
If they do not exist already, please contact your Snowflake administrator
to create the following objects for you:
- DATABASE: {snowflake_xcom_database},
- SCHEMA: {snowflake_xcom_schema},
- WAREHOUSE: {snowpark_warehouse} (if you want to use a Snowpark warehouse)
"""
)
snowpark_session.sql(
f"""CREATE TABLE IF NOT EXISTS
{snowflake_xcom_database}.
{snowflake_xcom_schema}.
{snowflake_xcom_table}
(
dag_id varchar NOT NULL,
task_id varchar NOT NULL,
run_id varchar NOT NULL,
multi_index integer NOT NULL,
key varchar NOT NULL,
value_type varchar NOT NULL,
value varchar NOT NULL
);
"""
).collect()
print(f"Table {snowflake_xcom_table} is ready!")
snowpark_session.sql(
f"""CREATE STAGE IF NOT EXISTS
{snowflake_xcom_database}.\
{snowflake_xcom_schema}.\
{snowflake_xcom_table_stage}
DIRECTORY = (ENABLE = TRUE)
ENCRYPTION = (TYPE = 'SNOWFLAKE_SSE');
"""
).collect()
print(f"Stage {snowflake_xcom_table_stage} is ready!")
create_snowflake_objects_obj = create_snowflake_objects(
snowflake_xcom_database=MY_SNOWFLAKE_XCOM_DATABASE,
snowflake_xcom_schema=MY_SNOWFLAKE_XCOM_SCHEMA,
snowflake_xcom_table=MY_SNOWFLAKE_XCOM_TABLE,
snowflake_xcom_table_stage=MY_SNOWFLAKE_XCOM_STAGE,
use_snowpark_warehouse=USE_SNOWPARK_WAREHOUSE,
snowpark_warehouse=MY_SNOWPARK_WAREHOUSE,
)
# use the Astro Python SDK to load data from a CSV file into Snowflake
load_file_obj = aql.load_file(
task_id="load_file",
input_file=File("include/data/ski_dataset.csv"),
output_table=Table(
metadata={
"database": MY_SNOWFLAKE_DATABASE,
"schema": MY_SNOWFLAKE_SCHEMA,
},
conn_id=SNOWFLAKE_CONN_ID,
name=MY_SNOWFLAKE_TABLE,
),
if_exists="replace",
)
# create a model registry in Snowflake
@task.snowpark_python(
snowflake_conn_id=SNOWFLAKE_CONN_ID,
)
def create_model_registry(demo_database, demo_schema):
from snowflake.ml.registry import model_registry
model_registry.create_model_registry(
session=snowpark_session,
database_name=demo_database,
schema_name=demo_schema,
)
# Tasks using the @task.snowpark_python decorator run in
# the regular Snowpark Python environment
@task.snowpark_python(
snowflake_conn_id=SNOWFLAKE_CONN_ID,
)
def transform_table_step_one(df):
from snowflake.snowpark.functions import col
import pandas as pd
import re
pattern = r"table=([^&]+)&schema=([^&]+)&database=([^&]+)"
match = re.search(pattern, df.uri)
formatted_result = f"{match.group(3)}.{match.group(2)}.{match.group(1)}"
df_snowpark = snowpark_session.table(formatted_result)
filtered_data = df_snowpark.filter(
(col("AFTERNOON_BEVERAGE") == "coffee")
| (col("AFTERNOON_BEVERAGE") == "tea")
| (col("AFTERNOON_BEVERAGE") == "snow_mocha")
| (col("AFTERNOON_BEVERAGE") == "hot_chocolate")
| (col("AFTERNOON_BEVERAGE") == "wine")
).collect()
filtered_df = pd.DataFrame(filtered_data, columns=df_snowpark.columns)
return filtered_df
# Tasks using the @task.snowpark_ext_python decorator can use an
# existing python environment
@task.snowpark_ext_python(snowflake_conn_id=SNOWFLAKE_CONN_ID, python=SNOWPARK_BIN)
def transform_table_step_two(df):
df_serious_skiers = df[df["HOURS_SKIED"] >= 1]
return df_serious_skiers
# Tasks using the @task.snowpark_virtualenv decorator run in a virtual
# environment created on the spot using the requirements specified
@task.snowpark_virtualenv(
snowflake_conn_id=SNOWFLAKE_CONN_ID,
requirements=["pandas", "scikit-learn"],
)
def train_beverage_classifier(
df,
database_name,
schema_name,
use_snowpark_warehouse=False,
snowpark_warehouse=None,
snowflake_regular_warehouse=None,
):
from sklearn.model_selection import train_test_split
import pandas as pd
from snowflake.ml.registry import model_registry
from snowflake.ml.modeling.linear_model import LogisticRegression
from uuid import uuid4
from snowflake.ml.modeling.preprocessing import OneHotEncoder, StandardScaler
registry = model_registry.ModelRegistry(
session=snowpark_session,
database_name=database_name,
schema_name=schema_name,
)
df.columns = [str(col).replace("'", "").replace('"', "") for col in df.columns]
X = df.drop(columns=["AFTERNOON_BEVERAGE", "SKIER_ID"])
y = df["AFTERNOON_BEVERAGE"]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
train_data = pd.concat([X_train, y_train], axis=1)
test_data = pd.concat([X_test, y_test], axis=1)
categorical_features = ["RESORT", "SKI_COLOR", "JACKET_COLOR", "HAD_LUNCH"]
numeric_features = ["HOURS_SKIED", "SNOW_QUALITY", "CM_OF_NEW_SNOW"]
label_col = ["AFTERNOON_BEVERAGE"]
scaler = StandardScaler(
input_cols=numeric_features,
output_cols=numeric_features,
drop_input_cols=True,
)
scaler.fit(train_data)
train_data_scaled = scaler.transform(train_data)
test_data_scaled = scaler.transform(test_data)
one_hot_encoder = OneHotEncoder(
input_cols=categorical_features,
output_cols=categorical_features,
drop_input_cols=True,
)
one_hot_encoder.fit(train_data_scaled)
train_data_scaled_encoded = one_hot_encoder.transform(train_data_scaled)
test_data_scaled_encoded = one_hot_encoder.transform(test_data_scaled)
feature_cols = train_data_scaled_encoded.drop(
columns=["AFTERNOON_BEVERAGE"]
).columns
classifier = LogisticRegression(
max_iter=10000, input_cols=feature_cols, label_cols=label_col
)
feature_cols = [str(col).replace('"', "") for col in feature_cols]
if use_snowpark_warehouse:
snowpark_session.use_warehouse(snowpark_warehouse)
classifier.fit(train_data_scaled_encoded)
score = classifier.score(test_data_scaled_encoded)
print(f"Accuracy: {score:.4f}")
y_pred = classifier.predict(test_data_scaled_encoded)
y_pred_proba = classifier.predict_proba(test_data_scaled_encoded)
# register the Snowpark model in the Snowflake model registry
registry.log_model(
model=classifier,
model_version=uuid4().urn,
model_name="Ski Beverage Classifier",
tags={"stage": "dev", "model_type": "LogisticRegression"},
)
if use_snowpark_warehouse:
snowpark_session.use_warehouse(snowflake_regular_warehouse)
snowpark_session.sql(
f"""ALTER WAREHOUSE
{snowpark_warehouse}
SUSPEND;"""
).collect()
y_pred_proba.columns = [
str(col).replace('"', "") for col in y_pred_proba.columns
]
y_pred.columns = [str(col).replace('"', "") for col in y_pred.columns]
prediction_results = pd.concat(
[
y_pred_proba[
[
"PREDICT_PROBA_snow_mocha",
"PREDICT_PROBA_tea",
"PREDICT_PROBA_coffee",
"PREDICT_PROBA_hot_chocolate",
"PREDICT_PROBA_wine",
]
],
y_pred[["OUTPUT_AFTERNOON_BEVERAGE"]],
y_test,
],
axis=1,
)
classes = classifier.to_sklearn().classes_
classes_df = pd.DataFrame(classes)
# convert to string column names for parquet serialization
prediction_results.columns = [
str(col).replace("'", "").replace('"', "")
for col in prediction_results.columns
]
classes_df.columns = ["classes"]
return {
"prediction_results": prediction_results,
"classes": classes_df,
}
# using a regular Airflow task to plot the results
@task
def plot_results(prediction_results):
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc, ConfusionMatrixDisplay
from sklearn.preprocessing import label_binarize
y_pred = prediction_results["prediction_results"]["OUTPUT_AFTERNOON_BEVERAGE"]
y_test = prediction_results["prediction_results"]["AFTERNOON_BEVERAGE"]
y_proba = prediction_results["prediction_results"][
[
"PREDICT_PROBA_coffee",
"PREDICT_PROBA_hot_chocolate",
"PREDICT_PROBA_snow_mocha",
"PREDICT_PROBA_tea",
"PREDICT_PROBA_wine",
]
]
y_score = y_proba.to_numpy()
classes = prediction_results["classes"].iloc[:, 0].values
y_test_bin = label_binarize(y_test, classes=classes)
fig, ax = plt.subplots(1, 2, figsize=(15, 6))
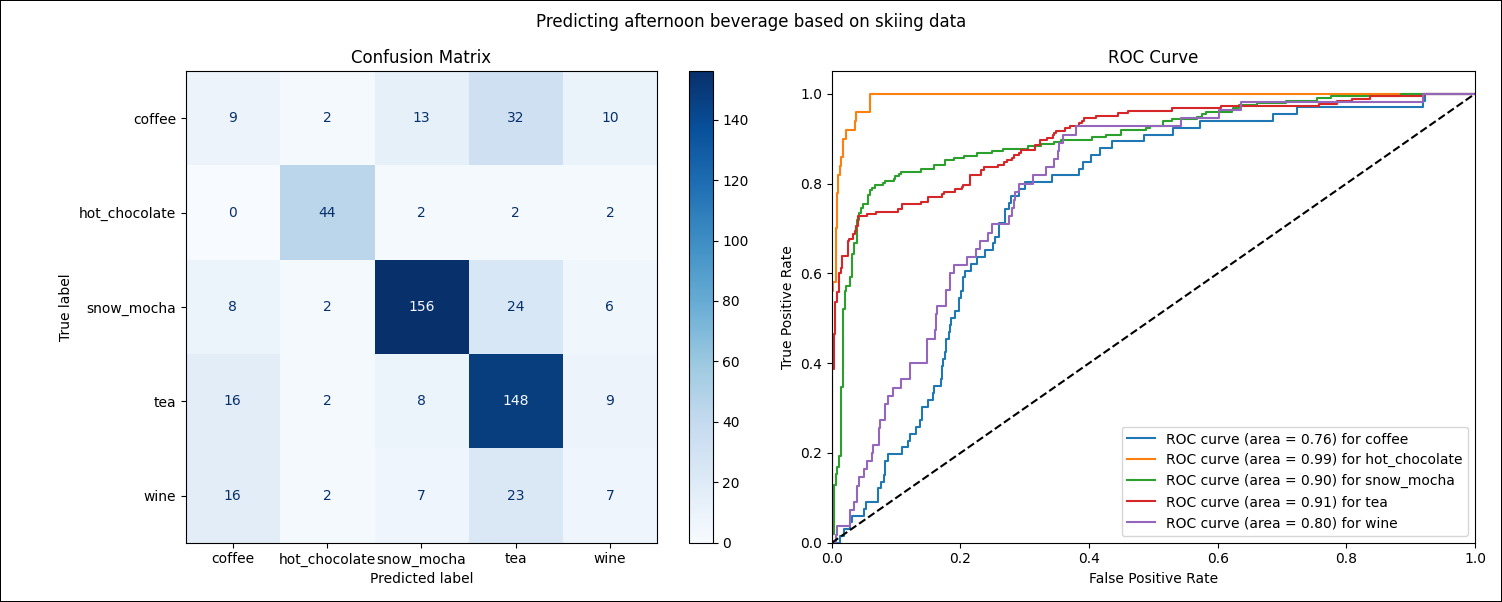
ConfusionMatrixDisplay.from_predictions(y_test, y_pred, ax=ax[0], cmap="Blues")
ax[0].set_title(f"Confusion Matrix")
fpr = dict()
tpr = dict()
roc_auc = dict()
for i, cls in enumerate(classes):
fpr[cls], tpr[cls], _ = roc_curve(y_test_bin[:, i], y_score[:, i])
roc_auc[cls] = auc(fpr[cls], tpr[cls])
ax[1].plot(
fpr[cls],
tpr[cls],
label=f"ROC curve (area = {roc_auc[cls]:.2f}) for {cls}",
)
ax[1].plot([0, 1], [0, 1], "k--")
ax[1].set_xlim([0.0, 1.0])
ax[1].set_ylim([0.0, 1.05])
ax[1].set_xlabel("False Positive Rate")
ax[1].set_ylabel("True Positive Rate")
ax[1].set_title(f"ROC Curve")
ax[1].legend(loc="lower right")
fig.suptitle("Predicting afternoon beverage based on skiing data")
plt.tight_layout()
plt.savefig(f"include/metrics.png")
if SETUP_TEARDOWN_SNOWFLAKE_CUSTOM_XCOM_BACKEND:
# clean up the XCOM table
@task.snowpark_ext_python(
snowflake_conn_id=SNOWFLAKE_CONN_ID,
python="/home/astro/.venv/snowpark/bin/python",
)
def cleanup_xcom_table(
snowflake_xcom_database,
snowflake_xcom_schema,
snowflake_xcom_table,
snowflake_xcom_stage,
):
snowpark_session.database = snowflake_xcom_database
snowpark_session.schema = snowflake_xcom_schema
snowpark_session.sql(
f"""DROP TABLE IF EXISTS
{snowflake_xcom_database}.
{snowflake_xcom_schema}.
{snowflake_xcom_table};"""
).collect()
snowpark_session.sql(
f"""DROP STAGE IF EXISTS
{snowflake_xcom_database}.
{snowflake_xcom_schema}.
{snowflake_xcom_stage};"""
).collect()
cleanup_xcom_table_obj = cleanup_xcom_table(
snowflake_xcom_database=MY_SNOWFLAKE_XCOM_DATABASE,
snowflake_xcom_schema=MY_SNOWFLAKE_XCOM_SCHEMA,
snowflake_xcom_table=MY_SNOWFLAKE_XCOM_TABLE,
snowflake_xcom_stage=MY_SNOWFLAKE_XCOM_STAGE,
)
# set dependencies
create_model_registry_obj = create_model_registry(
demo_database=MY_SNOWFLAKE_DATABASE, demo_schema=MY_SNOWFLAKE_SCHEMA
)
train_beverage_classifier_obj = train_beverage_classifier(
transform_table_step_two(transform_table_step_one(load_file_obj)),
database_name=MY_SNOWFLAKE_DATABASE,
schema_name=MY_SNOWFLAKE_SCHEMA,
use_snowpark_warehouse=USE_SNOWPARK_WAREHOUSE,
snowpark_warehouse=MY_SNOWPARK_WAREHOUSE,
snowflake_regular_warehouse=MY_SNOWFLAKE_REGULAR_WAREHOUSE,
)
chain(create_model_registry_obj, train_beverage_classifier_obj)
plot_results_obj = plot_results(train_beverage_classifier_obj)
if SETUP_TEARDOWN_SNOWFLAKE_CUSTOM_XCOM_BACKEND:
chain(create_snowflake_objects_obj, load_file_obj)
chain(
plot_results_obj,
cleanup_xcom_table_obj.as_teardown(setups=create_snowflake_objects_obj),
)
airflow_with_snowpark_tutorial()This DAG consists of eight tasks in a simple ML orchestration pipeline.
-
(Optional)
create_snowflake_objects: Creates the Snowflake objects required for the Snowflake custom XCom backend. This task uses the@task.snowflake_pythondecorator to run code within Snowpark, automatically instantiating a Snowpark session calledsnowpark_sessionfrom the connection ID provided to thesnowflake_conn_idparameter. This task is a setup task and is only shown in the DAG graph if you setSETUP_TEARDOWN_SNOWFLAKE_CUSTOM_XCOM_BACKENDtoTrue. See also Step 3.3. -
load_file: Loads the data from theski_dataset.csvfile into the Snowflake tableMY_SNOWFLAKE_TABLEusing the load_file operator from the Astro Python SDK. -
create_model_registry: Creates a model registry in Snowpark using the Snowpark ML package. Since the task is defined by the@task.snowflake_pythondecorator, the snowpark session is automatically instantiated from provided connection ID. -
transform_table_step_one: Transforms the data in the Snowflake table using Snowpark syntax to filter to only include rows of skiers that ordered the beverages we are interested in. Computation of this task runs within Snowpark. The resulting table is written to XCom as a pandas DataFrame. -
transform_table_step_two: Transforms the pandas DataFrame created by the upstream task to filter only for serious skiers (those who skied at least one hour that day). This task uses the@task.snowpark_ext_pythondecorator, running the code in the Snowpark virtual environment created in Step 1. The binary provided to thepythonparameter of the decorator determines which virtual environment to run a task in. The@task.snowpark_ext_pythondecorator works analogously to the @task.external_python decorator, except the code is executed within Snowpark's compute. -
train_beverage_classifier: Trains a Snowpark Logistic Regression model on the dataset, saves the model to the model registry, and creates predictions from a test dataset. This task uses the@task.snowpark_virtualenvdecorator to run the code in a newly created virtual environment within Snowpark's compute. Therequirementsparameter of the decorator specifies the packages to install in the virtual environment. The model predictions are saved to XCom as a pandas DataFrame. -
plot_metrics: Creates a plot of the model performance metrics and saves it to theincludedirectory. This task runs in the Airflow environment using the@taskdecorator. -
(Optional)
cleanup_xcom_table: Cleans up the Snowflake custom XCom backend by dropping theXCOM_TABLEandXCOM_STAGE. This task is a teardown task and is only shown in the DAG graph if you setSETUP_TEARDOWN_SNOWFLAKE_CUSTOM_XCOM_BACKENDtoTrue. See also Step 3.3.
-
-
(Optional) This DAG has two optional features you can enable.
-
If you want to use setup/ teardown tasks to create and clean up a Snowflake custom XCom backend for this DAG, set
SETUP_TEARDOWN_SNOWFLAKE_CUSTOM_XCOM_BACKENDtoTrue. This setting adds thecreate_snowflake_objectsandcleanup_xcom_tabletasks to your DAG and creates a setup/ teardown workflow. Note that your Snowflake account needs to haveACCOUNTADMINprivileges to perform the operations in thecreate_snowflake_objectstask and you need to define the environment variables described in Step 1.8 to enable the custom XCom backend. -
If you want to use a Snowpark-optimized warehouse for model training, set the
USE_SNOWPARK_WHvariable toTrueand provide your warehouse names toMY_SNOWPARK_WAREHOUSEandMY_SNOWFLAKE_REGULAR_WAREHOUSE. If thecreate_snowflake_objectstask is enabled, it creates theMY_SNOWPARK_WAREHOUSEwarehouse. Otherwise, you need to create the warehouse manually before running the DAG.
-
While this tutorial DAG uses a small dataset where model training can be accomplished using the standard Snowflake warehouse, Astronomer recommends using a Snowpark-optimized warehouse for model training in production.
Step 4: Run your DAG
-
Run
astro dev startin your Astro project to start up Airflow and open the Airflow UI atlocalhost:8080. -
In the Airflow UI, run the
airflow_with_snowpark_tutorialDAG by clicking the play button.
- Basic DAG
- DAG with setup/ teardown enabled


-
In the Snowflake UI, view the model registry to see the model that was created by the DAG. In a production context, you can pull a specific model from the registry to run predictions on new data.
-
Navigate to your
includedirectory to view themetrics.pngimage, which contains the model performance metrics shown at the start of this tutorial.
Conclusion
Congratulations! You trained a classification model in Snowpark using Airflow. This pipeline shows the three main options to run code in Snowpark using Airflow decorators:
@task.snowpark_pythonruns your code in a standard Snowpark environment. Use this decorator if you need to run code in Snowpark that does not require any additional packages that aren't preinstalled in a standard Snowpark environment. The corresponding traditional operator is the SnowparkPythonOperator.@task.snowpark_ext_pythonruns your code in a pre-existing virtual environment within Snowpark. Use this decorator when you want to reuse virtual environments in different tasks in the same Airflow instances, or your virtual environment takes a long time to build. The corresponding traditional operator is the SnowparkExternalPythonOperator.@task.snowpark_virtualenvruns your code in a virtual environment in Snowpark that is created at runtime for that specific task. Use this decorator when you want to tailor a virtual environment to a task and don't need to reuse it. The corresponding traditional operator is the SnowparkVirtualenvOperator.
Corresponding traditional operators are available:
- SnowparkPythonOperator, which you can import using
from snowpark_provider.operators.snowpark import SnowparkPythonOperator. - SnowparkExternalPythonOperator, available using
from snowpark_provider.operators.snowpark import SnowparkExternalPythonOperator. - SnowparkVirtualenvOperator, with the import
from snowpark_provider.operators.snowpark import SnowparkVirtualenvOperator.