Orchestrate OpenAI operations with Apache Airflow
OpenAI is an AI research and deployment company that provides an API for accessing state of the art models like GPT-4 and DALL·E 3. The OpenAI Airflow provider offers modules to easily integrate OpenAI with Airflow.
In this tutorial you'll use Airflow and the OpenAI Airflow provider to ask a question to Star Trek captains, create embeddings of the answers from each captain, and plot them in two dimensions.
Why use Airflow with OpenAI?
OpenAI offers a variety of powerful model endpoints for different tasks like text generation, vector embedding, and translation tasks. These models are used in both user-facing applications, such as chatbots, and internal applications, such as a smart search for internal knowledge base content.
Integrating OpenAI with Airflow into an end-to-end machine learning pipeline allows you to:
- Use Airflow's data-driven scheduling to run operations using OpenAI model endpoints based on upstream events in your data ecosystem, such as when new user input is ingested or a new dataset is available.
- Send several requests to a model endpoint in parallel based on upstream events in your data ecosystem or user input via Airflow params.
- Monitor the OpenAI service using Airflow alerts and protect against API rate limits and outages with Airflow retries.
- Use Airflow to orchestrate the creation of vector embeddings using OpenAI models, which is especially useful for large datasets that can't be processed automatically by vector databases.
Time to complete
This tutorial takes approximately 15 minutes to complete.
Assumed knowledge
To get the most out of this tutorial, make sure you have an understanding of:
- The basics of the OpenAI API. See OpenAI Introduction.
- The basics of vector embeddings. See the OpenAI Embeddings guide.
- Airflow fundamentals, such as writing DAGs and defining tasks. See Get started with Apache Airflow.
- Airflow operators. See Operators 101.
- Airflow hooks. See Hooks 101.
Prerequisites
- The Astro CLI.
- An OpenAI API key with at least tier 1 usage limits.
Step 1: Configure your Astro project
-
Create a new Astro project:
$ mkdir astro-openai-tutorial && cd astro-openai-tutorial
$ astro dev init -
Add the following lines to your
requirements.txtfile to install the OpenAI Airflow provider and other supporting packages:apache-airflow-providers-openai==1.0.0
openai==0.28.1
matplotlib==3.8.1
seaborn==0.13.0
scikit-learn==1.3.2
pandas==1.5.3
numpy==1.26.2
adjustText==0.8 -
To create an Airflow connection to OpenAI, add the following environment variables to your
.envfile. Make sure to replace<your-openai-api-key>with your own OpenAI API key.AIRFLOW_CONN_OPENAI_DEFAULT='{
"conn_type": "openai",
"password": "<your-openai-api-key>"
}'
Step 2: Create your DAG
-
In your
dagsfolder, create a file calledcaptains_dag.py. -
Copy the following code into the file.
"""
## Ask questions to Star Trek captains using OpenAI's LLMs, embed and visualize the results
This DAG shows how to use the OpenAI Airflow provider to interact with the OpenAI API.
The DAG asks a question to a list of Star Trek captains based on values you provide via
Airflow params, embeds the responses using the OpenAI text-embedding-ada-002 model,
and visualizes the embeddings in 2 dimensions using PCA, matplotlib and seaborn.
"""
from airflow.decorators import dag, task
from airflow.models.param import Param
from airflow.models.baseoperator import chain
from airflow.providers.openai.hooks.openai import OpenAIHook
from airflow.providers.openai.operators.openai import OpenAIEmbeddingOperator
from sklearn.metrics.pairwise import euclidean_distances
from sklearn.decomposition import PCA
from adjustText import adjust_text
from pendulum import datetime
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
import openai
OPENAI_CONN_ID = "openai_default"
IMAGE_PATH = "include/captains_plot.png"
star_trek_captains_list = [
"James T. Kirk",
"Jean-Luc Picard",
"Benjamin Sisko",
"Kathryn Janeway",
"Jonathan Archer",
"Christopher Pike",
"Michael Burnham",
"Saru",
]
@dag(
start_date=datetime(2023, 11, 1),
schedule=None,
catchup=False,
params={
"question": Param(
"Which is your favorite ship?",
type="string",
title="Question to ask the captains",
description="Enter what you would like to ask the captains.",
min_length=1,
max_length=500,
),
"captains_to_ask": Param(
star_trek_captains_list,
type="array",
description="List the captains whose answers you would like to compare. "
+ "Suggestions: "
+ ", ".join(star_trek_captains_list),
),
"max_tokens_answer": Param(
100,
type="integer",
description="Maximum number of tokens to generate for the answer.",
),
"randomness_of_answer": Param(
10,
type="integer",
description=(
"Enter the desired randomness of the answer on a scale"
+ "from 0 (no randomness) to 20 (full randomness). "
+ "This setting corresponds to 10x the temperature setting in the OpenAI API."
),
min=0,
max=20,
),
},
)
def captains_dag():
@task
def get_captains_list(**context):
"Pull the list of captains to ask from the context."
captains_list = context["params"]["captains_to_ask"]
return captains_list
@task
def ask_a_captain(open_ai_conn_id: str, captain_to_ask, **context):
"Ask a captain a question using gpt-3.5-turbo."
question = context["params"]["question"]
max_tokens_answer = context["params"]["max_tokens_answer"]
randomness_of_answer = context["params"]["randomness_of_answer"]
hook = OpenAIHook(conn_id=open_ai_conn_id)
openai.api_key = hook._get_api_key()
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": f"You are captain {captain_to_ask}."},
{"role": "user", "content": question},
],
temperature=randomness_of_answer / 10,
max_tokens=max_tokens_answer,
)
response = response.choices[0]["message"]["content"]
print(f"Your Question: {question}")
print(f"Captain {captain_to_ask} said: {response}")
return response
captains_list = get_captains_list()
captain_responses = ask_a_captain.partial(open_ai_conn_id=OPENAI_CONN_ID).expand(
captain_to_ask=captains_list
)
get_embeddings = OpenAIEmbeddingOperator.partial(
task_id="get_embeddings",
conn_id=OPENAI_CONN_ID,
model="text-embedding-ada-002",
).expand(input_text=captain_responses)
@task
def plot_embeddings(embeddings, text_labels, file_name="embeddings_plot.png"):
"Plot the embeddings of the captain responses."
pca = PCA(n_components=2)
reduced_embeddings = pca.fit_transform(embeddings)
plt.figure(figsize=(10, 8))
df_embeddings = pd.DataFrame(reduced_embeddings, columns=["PC1", "PC2"])
sns.scatterplot(
df_embeddings, x="PC1", y="PC2", s=100, color="gold", edgecolor="black"
)
font_style = {"color": "black"}
texts = []
for i, label in enumerate(text_labels):
texts.append(
plt.text(
reduced_embeddings[i, 0],
reduced_embeddings[i, 1],
label,
fontdict=font_style,
fontsize=15,
)
)
# prevent overlapping labels
adjust_text(texts, arrowprops=dict(arrowstyle="->", color="red"))
distances = euclidean_distances(reduced_embeddings)
np.fill_diagonal(distances, np.inf) # exclude cases where the distance is 0
n = distances.shape[0]
distances_list = [
(distances[i, j], (i, j)) for i in range(n) for j in range(i + 1, n)
]
distances_list.sort(reverse=True)
legend_handles = []
for dist, (i, j) in distances_list:
(line,) = plt.plot(
[reduced_embeddings[i, 0], reduced_embeddings[j, 0]],
[reduced_embeddings[i, 1], reduced_embeddings[j, 1]],
"gray",
linestyle="--",
alpha=0.3,
)
legend_handles.append(line)
legend_labels = [
f"{text_labels[i]} - {text_labels[j]}: {dist:.2f}"
for dist, (i, j) in distances_list
]
for i in range(len(reduced_embeddings)):
for j in range(i + 1, len(reduced_embeddings)):
plt.plot(
[reduced_embeddings[i, 0], reduced_embeddings[j, 0]],
[reduced_embeddings[i, 1], reduced_embeddings[j, 1]],
"gray",
linestyle="--",
alpha=0.5,
)
plt.legend(
legend_handles,
legend_labels,
title="Distances",
loc="center left",
bbox_to_anchor=(1, 0.5),
)
plt.tight_layout()
plt.title(
"2D Visualization of captain responses", fontsize=16, fontweight="bold"
)
plt.xlabel("PCA Component 1", fontdict=font_style)
plt.ylabel("PCA Component 2", fontdict=font_style)
plt.savefig(file_name, bbox_inches="tight")
plt.close()
chain(
get_embeddings,
plot_embeddings(
get_embeddings.output,
text_labels=captains_list,
file_name=IMAGE_PATH,
),
)
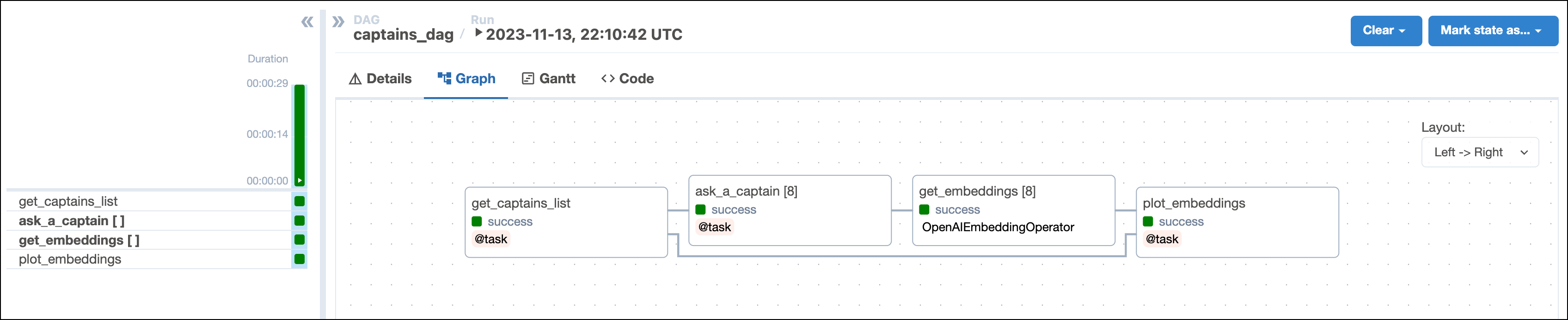
captains_dag()This DAG consists of four tasks to make a simple MLOps pipeline.
- The
get_captains_listtask fetches the list of Star Trek captains you want to ask your question to. You'll provide the list of captains when you run the DAG with Airflow params. - The
ask_a_captaintask uses the OpenAIHook to connect to the OpenAI API. It then uses the chat completion endpoint to generate answers to the question you provide. This task is dynamically mapped over the list of captains to generate one dynamically mapped task instance per captain. - The
get_embeddingstask is defined using the OpenAIEmbeddingOperator to generate vector embeddings of the answers generated by the upstreamask_a_captaintask. This task is dynamically mapped over the list of answers to retrieve one set of embeddings per answer. This pattern allows for efficient parallelization of the vector embedding generation. - The
plot_embeddingstask takes the embeddings created by the upstream task and performs dimensionality reduction using PCA to plot the embeddings in two dimensions.
- The
Step 3: Run your DAG
-
Run
astro dev startin your Astro project to start Airflow, then open the Airflow UI atlocalhost:8080. -
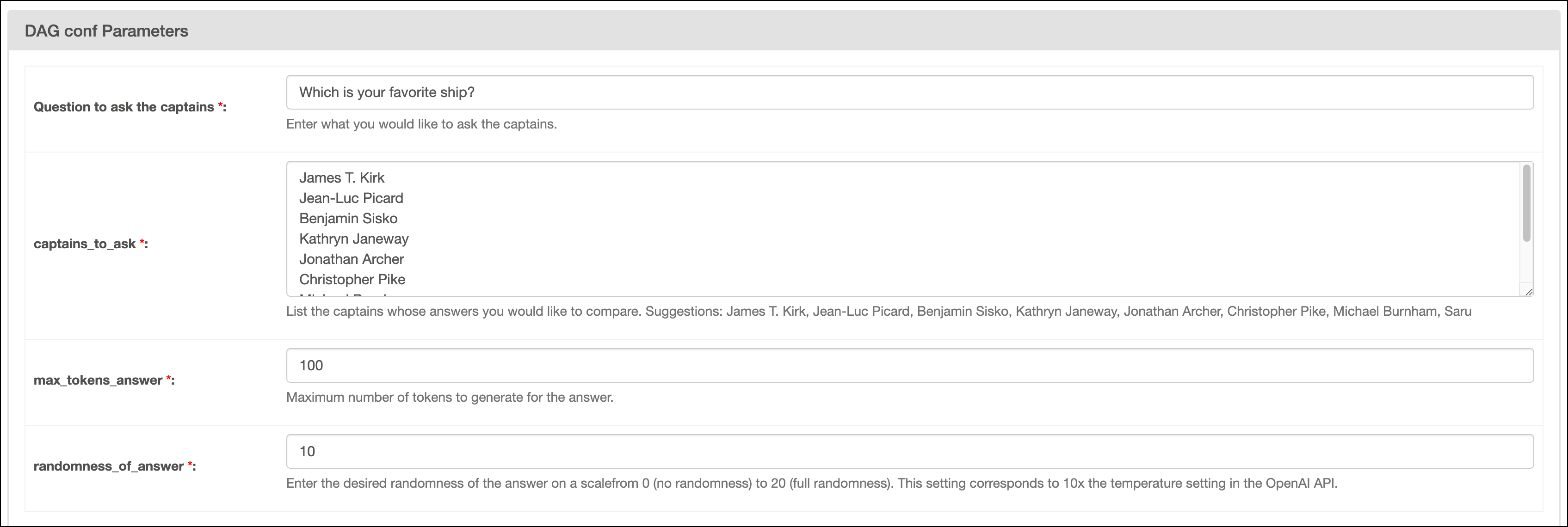
In the Airflow UI, run the
captains_dagDAG by clicking the play button. Then, provide Airflow params for:Question to ask the captain: The question you want to ask the captains.captains_to_ask: A list of Star Trek captains you want to ask the question to. Make sure to create one line per captain and to provide at least two names.max_tokens_answer: The maximum number of tokens available for the answer.randomness_of_answer: The randomness of the answer. The value provided is divided by 10 and given to thetemperatureparameter of the chat completion endpoint. The scale for the param ranges from 0 to 20, with 0 being the most deterministic and 20 being the most random.
-
After the DAG run completed, go to the
includefolder to view the image file created by theplot_embeddingstask. The image should look similar to the one below.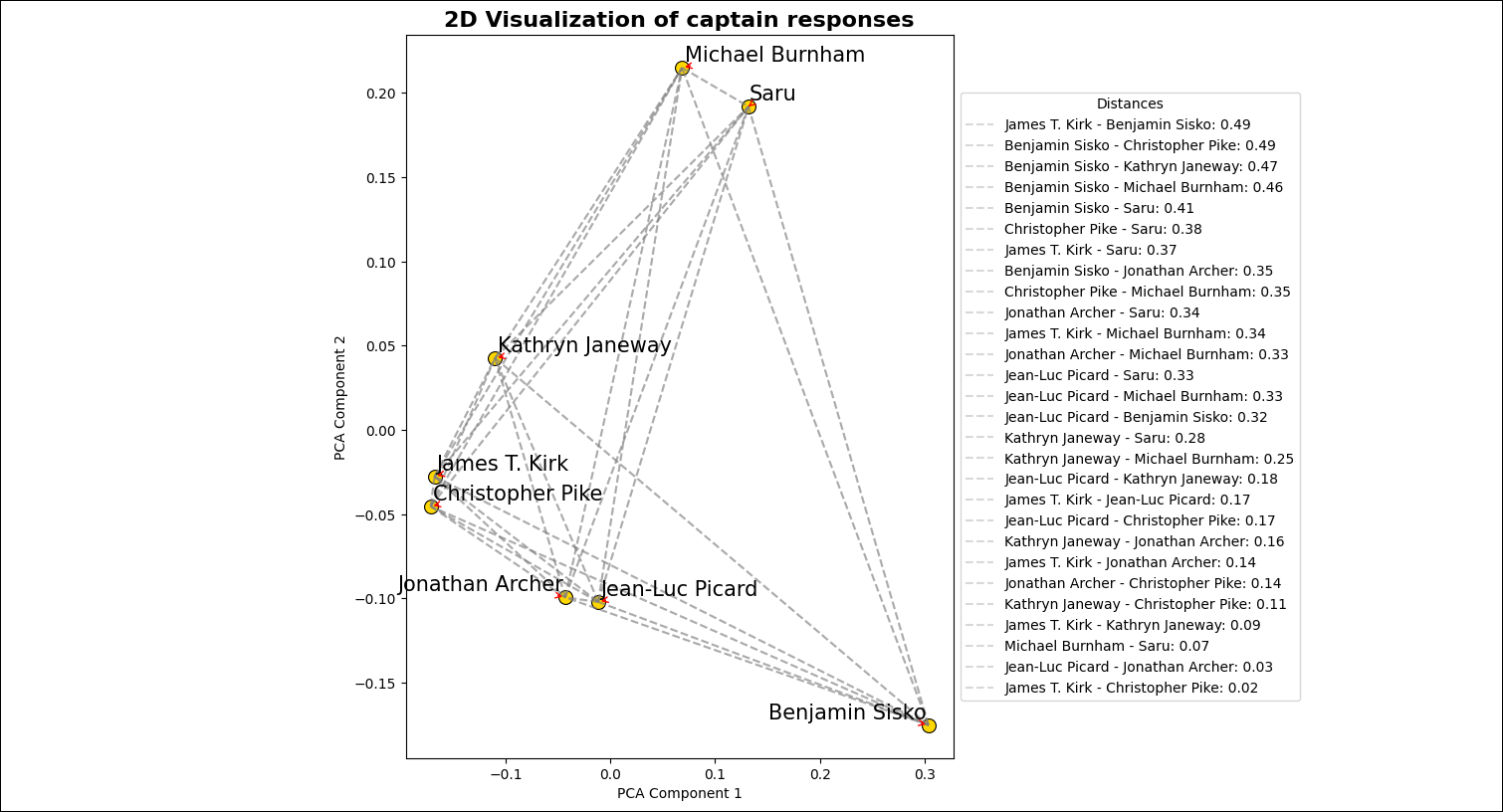
Conclusion
Congratulations! You used Airflow and OpenAI to get answers from your favorite Star Trek captains and compare them visually. You can now use Airflow to orchestrate OpenAI operations in your own machine learning pipelines. 🖖