ELT with Snowflake and Apache Airflow® for eCommerce
The ELT with Snowflake and Apache Airflow® GitHub repository is a free and open-source reference architecture showing how to use Apache Airflow® with Snowflake to build an end-to-end ELT pipeline. The pipeline ingests data from an eCommerce store's API, completes several transformation steps in SQL, and displays the data in a dashboard. A demo of the architecture is shown in the Implementing reliable ETL & ELT pipelines with Airflow and Snowflake webinar.
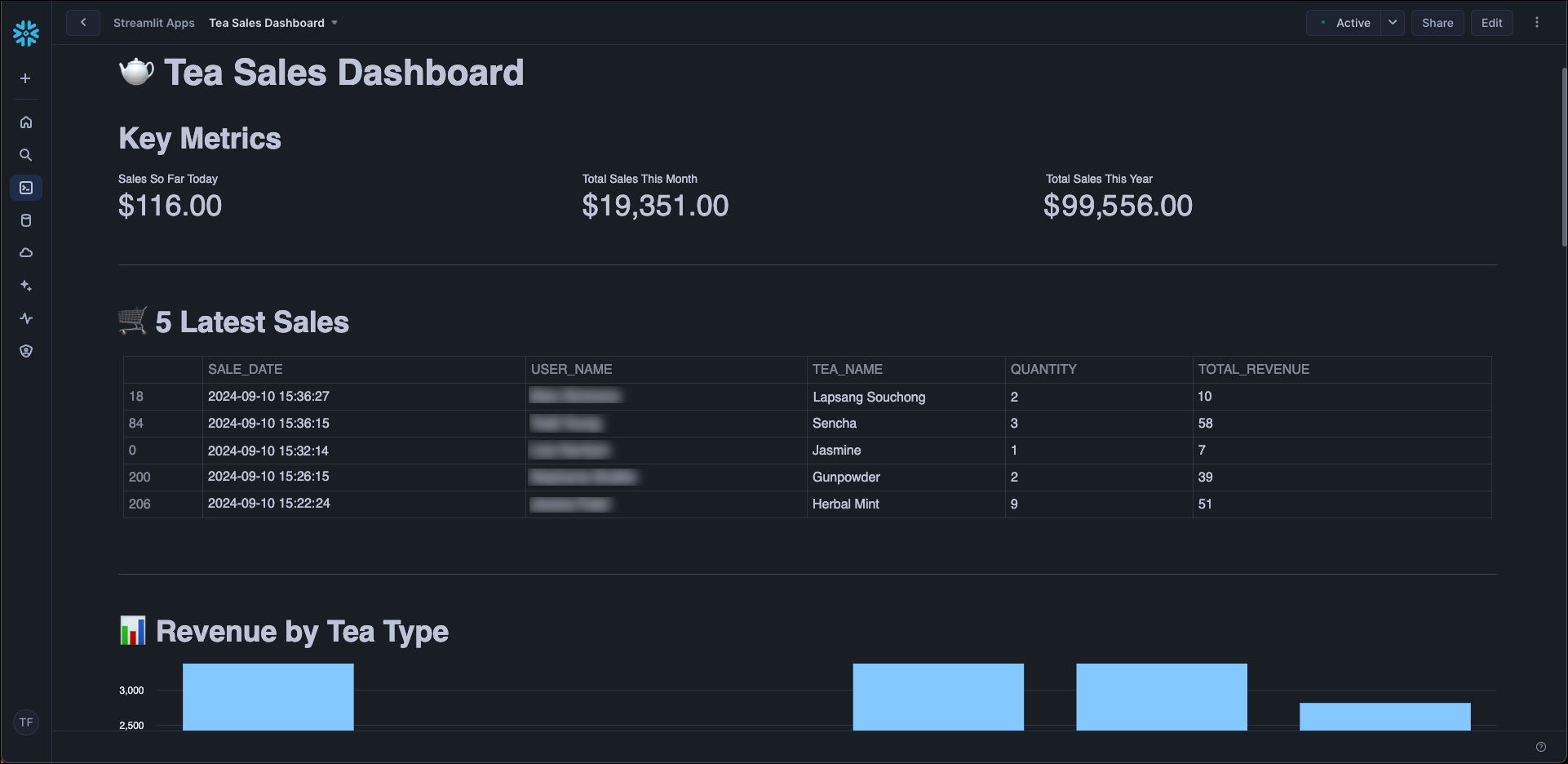
This reference architecture was created as a learning tool to demonstrate how to use Apache Airflow to orchestrate data ingestion into object storage and a data warehouse, as well as how to use Snowflake to transform the data in several steps and display it in a dashboard. You can adapt the pipeline for your use case by ingesting data from other sources, adjusting the SQL transformations, and changing the dashboard to fit your needs.
Architecture
This reference architecture consists of 4 main components:
- Extraction: Data is extracted from an eCommerce store's API and stored in an object storage bucket.
- Loading: The extracted data is loaded into Snowflake, a cloud-based data warehouse.
- Transformation: The data is transformed in several steps using SQL queries in Snowflake.
- Dashboard: The transformed data is displayed in a dashboard using Streamlit.
Additionally, two DAGs move the raw data between different object storage locations (ingest/stage/archive) to archive records that have been processed.
Airflow features
The DAGs in this reference architecture highlight several key Airflow best practices and features:
- Object Storage: Interaction with files in object storage is simplified using the experimental Airflow Object Storage API. This API allows for easy streaming of large files between object storage locations.
- Data-driven scheduling: The DAGs in this reference architecture run on data-driven schedules as soon as the data they operate on is updated.
- Data quality checks: Data quality checks are performed on the base Snowflake tables using the SQLColumnCheckOperator and the SQLTableCheckOperator. There are both, quality checks that stop the pipeline upon failure, and check that only send a notification.
- Notifications: If certain data quality checks fail, a Slack notification is automatically sent to the data quality team using an
on_failure_callbackat the task-group-level. - Airflow retries: To protect against transient API failures, all tasks are configured to automatically retry after an adjustable delay.
- Dynamic task mapping: Interaction with files in object storage is parallelized per type of record using dynamic task mapping.
- Custom XCom Backend: In the extraction step, new records are passed through XCom to the next task. XComs are stored in S3 using an Object Storage custom XCom backend.
- Modularization: SQL queries are stored in the
includefolder and imported into the DAG file to be used in SQLExecuteQueryOperator tasks. This makes the DAG code more readable and offers the ability to reuse SQL queries across multiple DAGs. Additionally, some Python functions and data quality check definitions are modularized as well.
Next Steps
If you'd like to build your own ELT/ETL pipeline with Snowflake and Apache Airflow®, feel free to fork the repository and adapt it to your use case. We recommend deploying the Airflow pipelines using a free trial of Astro.