Use Apache Kafka with Apache Airflow
Apache Kafka is an open source tool for handling event streaming. Combining Kafka and Airflow allows you to build powerful pipelines that integrate streaming data with batch processing. In this tutorial, you'll learn how to install and use the Kafka Airflow provider to interact directly with Kafka topics.
While it is possible to manage a Kafka cluster with Airflow, be aware that Airflow itself should not be used for streaming or low-latency processes. See the Best practices section for more information.
Time to complete
This tutorial takes approximately 1 hour to complete.
Assumed knowledge
To get the most out of this tutorial, make sure you have an understanding of:
- The basics of Apache Kafka. See the official Introduction to Kafka.
- Airflow fundamentals, such as writing DAGs and defining tasks. See Get started with Apache Airflow.
- Airflow operators. See Operators 101.
Quickstart
If you have a GitHub account, you can use the quickstart repository for this tutorial, which automatically starts up Airflow, initiates a local Kafka cluster, and configures all necessary connections. Clone the quickstart repository and then skip to Step 6: Run the DAGs.
Prerequisites
- A Kafka cluster with a topic. This tutorial uses a cluster hosted by Confluent Cloud, which has a free trial option. See the Confluent documentation for how to create a Kafka cluster and topic in Confluent Cloud.
- The Astro CLI.
To connect a local Kafka cluster to an Airflow instance running in Docker, set the following properties in your Kafka cluster's server.properties file before starting your Kafka cluster:
listeners=PLAINTEXT://:9092,DOCKER_HACK://:19092
advertised.listeners=PLAINTEXT://localhost:9092,DOCKER_HACK://host.docker.internal:19092
listener.security.protocol.map=PLAINTEXT:PLAINTEXT,DOCKER_HACK:PLAINTEXT
You can learn more about connecting to local Kafka from within a Docker container in Confluent's Documentation.
Step 1: Configure your Astro project
-
Create a new Astro project:
$ mkdir astro-kafka-tutorial && cd astro-kafka-tutorial
$ astro dev init -
Add the following packages to your
packages.txtfile:build-essential
librdkafka-dev -
Add the following packages to your
requirements.txtfile:confluent-kafka==2.1.1
apache-airflow-providers-apache-kafka==1.0.0 -
Run the following command to start your project in a local environment:
astro dev start
Step 2: Create two Kafka connections
The Kafka Airflow provider uses a Kafka connection assigned to the kafka_conn_id parameter of each operator to interact with a Kafka cluster. For this tutorial you define two Kafka connections, because two different consumers will be created.
-
In your web browser, go to
localhost:8080to access the Airflow UI. -
Click Admin > Connections > + to create a new connection.
-
Name your connection
kafka_defaultand select the Apache Kafka connection type. Provide the details for the connection to your Kafka cluster as JSON in the Extra field.If you connect to a local Kafka cluster created with the
server.propertiesin the info box from the Prerequisites section, use the following configuration:{
"bootstrap.servers": "kafka:19092",
"group.id": "group_1",
"security.protocol": "PLAINTEXT",
"auto.offset.reset": "beginning"
}The key-value pairs for your connection depend on what kind of Kafka cluster you are connecting to. Most operators in the Kafka Airflow provider mandate that you define the
bootstrap.serverskey. You can find a full list of optional connection parameters in the librdkafka documentation. -
Click Save.
-
Create a second new connection.
-
Name your second connection
kafka_listenerand select theApache Kafkaconnection type. Provide the same details as you did in Step 2, but set thegroup.idtogroup_2. You must have a second connection with a differentgroup.idbecause the DAGs in this tutorial have two consuming tasks that consume messages from the same Kafka topic. Learn more in Kafka's Consumer Configs documentation. -
Click Save.
Step 3: Create a DAG with a producer and a consumer task
The Kafka Airflow provider package contains a ProduceToTopicOperator, which you can use to produce messages directly to a Kafka topic, and a ConsumeFromTopicOperator, which you can use to directly consume messages from a topic.
-
Create a new file in your
dagsfolder calledproduce_consume_treats.py. -
Copy and paste the following code into the
produce_consume_treats.pyfile:"""
### DAG which produces to and consumes from a Kafka cluster
This DAG will produce messages consisting of several elements to a Kafka cluster and consume
them.
"""
from airflow.decorators import dag, task
from pendulum import datetime
from airflow.providers.apache.kafka.operators.produce import ProduceToTopicOperator
from airflow.providers.apache.kafka.operators.consume import ConsumeFromTopicOperator
import json
import random
YOUR_NAME = "<your name>"
YOUR_PET_NAME = "<your (imaginary) pet name>"
NUMBER_OF_TREATS = 5
KAFKA_TOPIC = "my_topic"
def prod_function(num_treats, pet_name):
"""Produces `num_treats` messages containing the pet's name, a randomly picked
pet mood post treat and whether or not it was the last treat in a series."""
for i in range(num_treats):
final_treat = False
pet_mood_post_treat = random.choices(
["content", "happy", "zoomy", "bouncy"], weights=[2, 2, 1, 1], k=1
)[0]
if i + 1 == num_treats:
final_treat = True
yield (
json.dumps(i),
json.dumps(
{
"pet_name": pet_name,
"pet_mood_post_treat": pet_mood_post_treat,
"final_treat": final_treat,
}
),
)
def consume_function(message, name):
"Takes in consumed messages and prints its contents to the logs."
key = json.loads(message.key())
message_content = json.loads(message.value())
pet_name = message_content["pet_name"]
pet_mood_post_treat = message_content["pet_mood_post_treat"]
print(
f"Message #{key}: Hello {name}, your pet {pet_name} has consumed another treat and is now {pet_mood_post_treat}!"
)
@dag(
start_date=datetime(2023, 4, 1),
schedule=None,
catchup=False,
render_template_as_native_obj=True,
)
def produce_consume_treats():
@task
def get_your_pet_name(pet_name=None):
return pet_name
@task
def get_number_of_treats(num_treats=None):
return num_treats
@task
def get_pet_owner_name(your_name=None):
return your_name
produce_treats = ProduceToTopicOperator(
task_id="produce_treats",
kafka_config_id="kafka_default",
topic=KAFKA_TOPIC,
producer_function=prod_function,
producer_function_args=["{{ ti.xcom_pull(task_ids='get_number_of_treats')}}"],
producer_function_kwargs={
"pet_name": "{{ ti.xcom_pull(task_ids='get_your_pet_name')}}"
},
poll_timeout=10,
)
consume_treats = ConsumeFromTopicOperator(
task_id="consume_treats",
kafka_config_id="kafka_default",
topics=[KAFKA_TOPIC],
apply_function=consume_function,
apply_function_kwargs={
"name": "{{ ti.xcom_pull(task_ids='get_pet_owner_name')}}"
},
poll_timeout=20,
max_messages=20,
max_batch_size=20,
)
[
get_your_pet_name(YOUR_PET_NAME),
get_number_of_treats(NUMBER_OF_TREATS),
] >> produce_treats
get_pet_owner_name(YOUR_NAME) >> consume_treats
produce_treats >> consume_treats
produce_consume_treats()This DAG produces messages to a Kafka topic (
KAFKA_TOPIC) and consumes them.- The
produce_treatstask retrieves the number of treats (num_treats) to give to your pet from the upstreamget_number_of_treatstask. Then, the task supplies the number of treats to theproducer_functionas a positional argument with theproducer_function_argsparameter. In a similar process, the task also retrieves the name of your pet from the upstreamget_your_pet_nametask and provides it as a kwarg toproducer_function_kwargs. - Next, the
produce_treatstask writes one message for every treat to a Kafka topic. Each message contains the pet name, a randomly picked pet mood after the treat has been given, and whether or not a treat was the last one in a series. TheProduceToTopicOperatoraccomplishes this by using a function passed to itsproducer_functionparameter, which returns a generator containing key-value pairs. - The
consume_treatstask consumes messages from the same Kafka topic and modifies them to print a string to the logs using the callable provided to theapply_functionparameter. This task also retrieves a value from an upstream task and supplies it as a kwarg to theapply_functionwith theapply_function_kwargsparameter.
- The
-
Navigate to the Airflow UI (
localhost:8080if you are running Airflow locally) and manually run your DAG. -
View the produced events in your Kafka cluster. The following example screenshot shows four messages that have been produced to a topic called
test_topic_1in Confluent Cloud.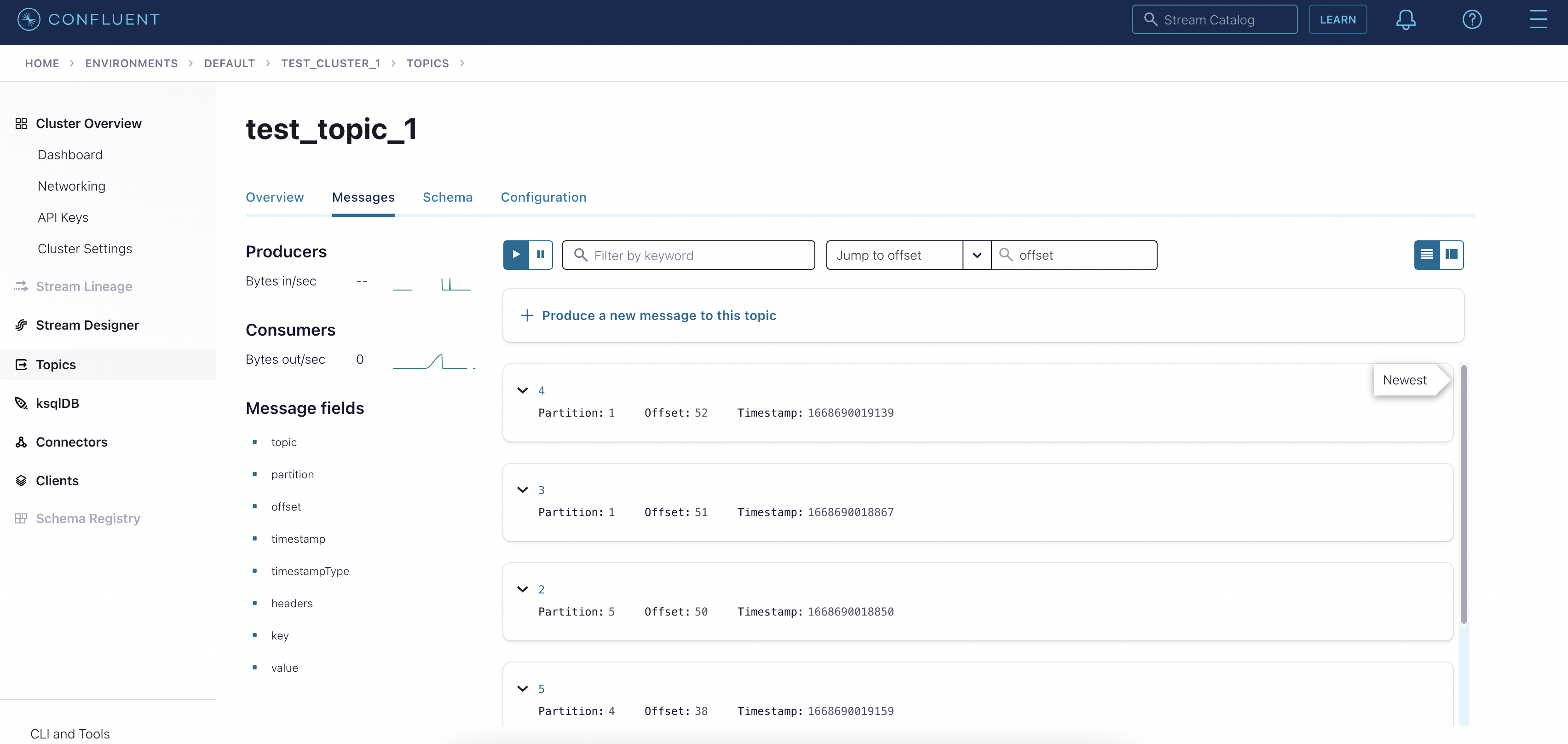
-
View the logs of your
consume_treatstask, which shows a list of the consumed events.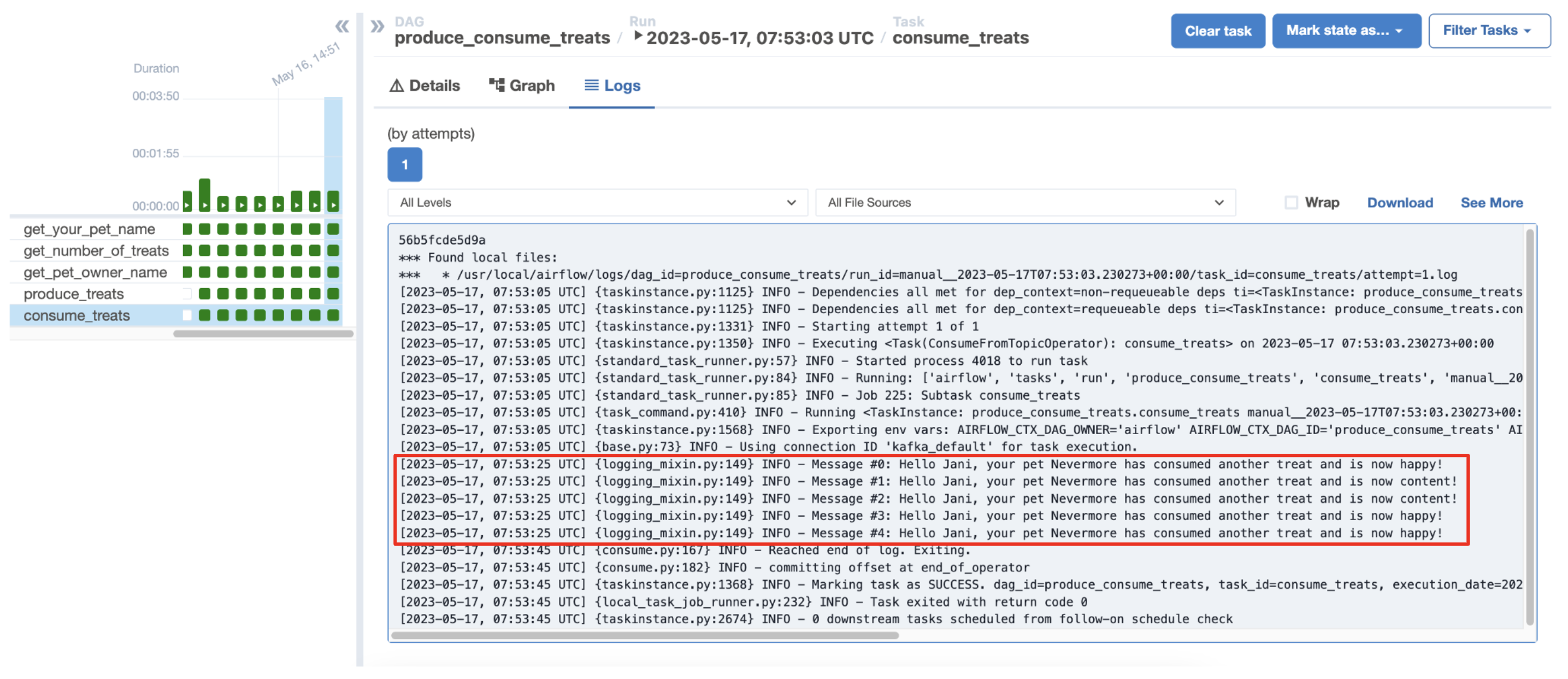
If you defined a schema for your Kafka topic, the generator needs to return compatible objects. In this example, the generator produces a JSON value.
The ConsumeFromTopicOperator can replace classical sinks by containing the logic to write messages to a storage destination in its apply_function. This gives you the advantage of being able to use Airflow to schedule message consumption from a Kafka topic based on complex logic embedded in your wider data ecosystem. For example, you can write messages to S3 using the S3CreateObjectOperator, which depends on other upstream task having completed successfully, such as the creation of a specific S3 bucket.
Step 4: Create a listener DAG
Airflow can run a function when a specific message appears in your Kafka topic. The AwaitMessageTriggerFunctionSensor is a deferrable operator that listens to your Kafka topic for a message that fulfills specific criteria, which, when met, runs the callable provided to event_triggered_function. The TriggerDagRunOperator can be used within the event_triggered_function to initiate a run of a downstream DAG.
-
Create a new file in your
dagsfolder calledlisten_to_the_stream.py. -
Copy and paste the following code into the file:
"""
### DAG continuously listening to a Kafka topic for a specific message
This DAG will always run and asynchronously monitor a Kafka topic for a message
which causes the funtion supplied to the `apply_function` parameter to return a value.
If a value is returned by the `apply_function`, the `event_triggered_function` is
executed. Afterwards the task will go into a deferred state again.
"""
from airflow.decorators import dag
from pendulum import datetime
from airflow.providers.apache.kafka.sensors.kafka import (
AwaitMessageTriggerFunctionSensor,
)
from airflow.operators.trigger_dagrun import TriggerDagRunOperator
import json
import uuid
PET_MOODS_NEEDING_A_WALK = ["zoomy", "bouncy"]
KAFKA_TOPIC = "my_topic"
def listen_function(message, pet_moods_needing_a_walk=[]):
"""Checks if the message received indicates a pet is in
a mood listed in `pet_moods_needing_a_walk` when they received the last
treat of a treat-series."""
message_content = json.loads(message.value())
print(f"Full message: {message_content}")
pet_name = message_content["pet_name"]
pet_mood_post_treat = message_content["pet_mood_post_treat"]
final_treat = message_content["final_treat"]
if final_treat:
if pet_mood_post_treat in pet_moods_needing_a_walk:
return pet_name, pet_mood_post_treat
def event_triggered_function(event, **context):
"Kicks off a downstream DAG with conf and waits for its completion."
pet_name = event[0]
pet_mood_post_treat = event[1]
print(
f"Due to {pet_name} being in a {pet_mood_post_treat} mood, a walk is being initiated..."
)
# use the TriggerDagRunOperator (TDRO) to kick off a downstream DAG
TriggerDagRunOperator(
trigger_dag_id="walking_my_pet",
task_id=f"triggered_downstream_dag_{uuid.uuid4()}",
wait_for_completion=True, # wait for downstream DAG completion
conf={"pet_name": pet_name},
poke_interval=5,
).execute(context)
print(f"The walk has concluded and {pet_name} is now happily taking a nap!")
@dag(
start_date=datetime(2023, 4, 1),
schedule="@continuous",
max_active_runs=1,
catchup=False,
render_template_as_native_obj=True,
)
def listen_to_the_stream():
listen_for_mood = AwaitMessageTriggerFunctionSensor(
task_id="listen_for_mood",
kafka_config_id="kafka_listener",
topics=[KAFKA_TOPIC],
# the apply function will be used from within the triggerer, this is
# why it needs to be a dot notation string
apply_function="listen_to_the_stream.listen_function",
poll_interval=5,
poll_timeout=1,
apply_function_kwargs={"pet_moods_needing_a_walk": PET_MOODS_NEEDING_A_WALK},
event_triggered_function=event_triggered_function,
)
listen_to_the_stream()This DAG has one task called
listen_for_moodwhich uses the AwaitMessageTriggerFunctionSensor to listen to messages in all topics supplied to itstopicsparameters. For each message that is consumed, the following actions are performed:- The
listen_functionsupplied to theapply_functionparameter of the AwaitMessageTriggerFunctionSensor consumes and processes the message. Thelisten_functionis provided as a dot notation string, which is necessary because the Airflow triggerer component needs to access this function. - If the message consumed causes the
listen_functionto return a value, a TriggerEvent fires. - After a TriggerEvent fires, the AwaitMessageTriggerFunctionSensor executes the function provided to the
event_triggered_functionparameter. In this example, theevent_triggered_functionstarts a downstream DAG using the.execute()method of theTriggerDagRunOperator. - After the
event_triggered_functioncompletes, the AwaitMessageTriggerFunctionSensor returns to a deferred state.
The AwaitMessageTriggerFunctionSensor always runs and listens. If the task fails, like if a malformed message is consumed, the DAG completes as
failedand automatically starts its next DAG run because of the@continuousschedule. - The
When working locally, you need to restart your Airflow instance to apply changes to the apply_function of the AwaitMessageTriggerFunctionSensor because the function is imported into the Triggerer, which does not periodically restart. To restart Airflow, run astro dev restart in your terminal. Changes to the event_triggered_function of the AwaitMessageTriggerFunctionSensor do not require a restart of your Airflow instance.
On Astro, the Triggerer is restarted automatically when a new image is deployed, but not on dag-only deploys, see Deploy DAGs to Astro.
Step 5: Create a downstream DAG
The event_triggered_function of the AwaitMessageTriggerFunctionSensor operator starts a downstream DAG. This example shows how to implement a dependency based on messages that appear in your Kafka topic.
-
Create a new file in your
dagsfolder calledwalking_my_pet.py. -
Copy and paste the following code into the file:
"""
### Simple DAG that runs one task with params
This DAG uses one string type param and uses it in a python decorated task.
"""
from airflow.decorators import dag, task
from pendulum import datetime
from airflow.models.param import Param
import random
@dag(
start_date=datetime(2023, 4, 1),
schedule=None,
catchup=False,
render_template_as_native_obj=True,
params={"pet_name": Param("Undefined!", type="string")},
)
def walking_my_pet():
@task
def walking_your_pet(**context):
pet_name = context["params"]["pet_name"]
minutes = random.randint(2, 10)
print(f"{pet_name} has been on a {minutes} minute walk!")
walking_your_pet()
walking_my_pet()This DAG acts as a downstream dependency to the
listen_to_the_streamDAG. You can add any tasks to this DAG.
Step 6: Run the DAGs
Now that all three DAGs are ready, run them to see how they work together.
-
Make sure you unpause all DAGs in the Airflow UI and that your Kafka cluster is running.
-
The
listen_to_the_streamDAG immediately starts running after it unpauses and thelisten_for_moodtask goes into a Deferred state, which is indicated with a purple square in the Airflow UI.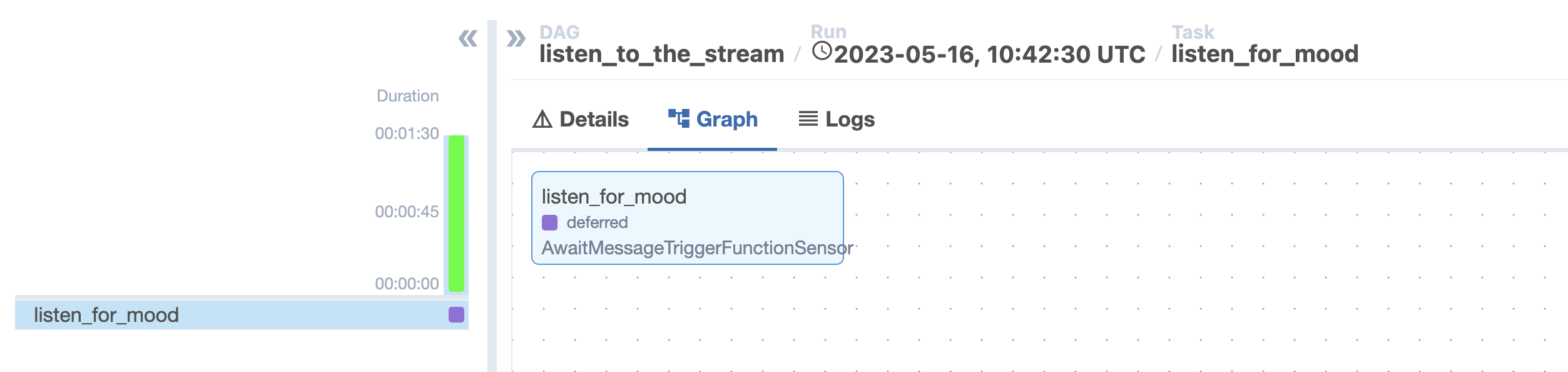
-
Manually run the
produce_consume_treatsDAG to give your pet some treats and produce a few messages to the Kafka cluster. -
Check the logs of the
listen_for_moodtask in thelisten_to_the_streamDAG to see if a message fitting the criteria defined by thelisten_functionhas been detected. You might need to run theproduce_consume_treatsDAG a couple of times for a message to appear.If the TriggerEvent of the
listen_for_moodtask fires, thelisten_for_moodtask logs show thewalking_my_petDAG initiating.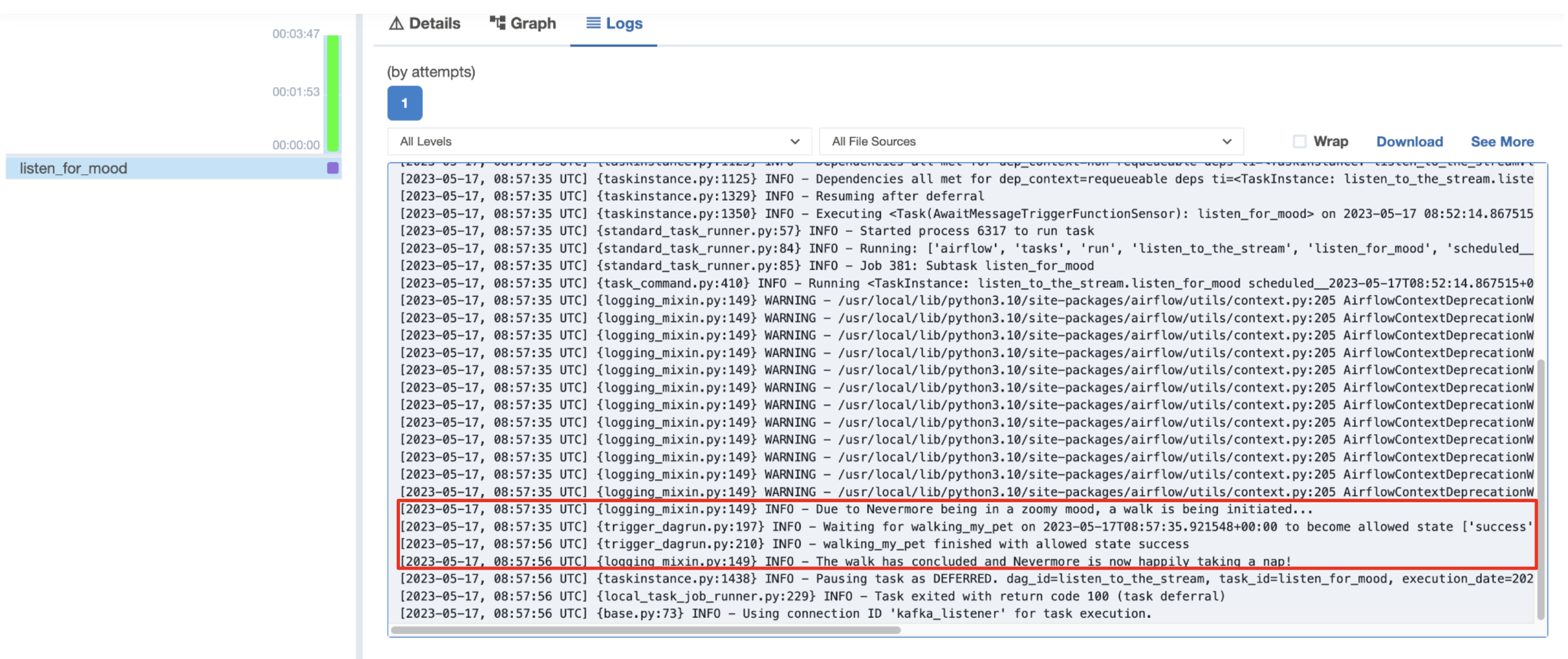
-
Finally, check the logs of the
walking_my_pettask to see how long your pet enjoyed their walk!
Best practices
Apache Kafka is a tool optimized for streaming messages at high frequencies, for example in an IoT application. Airflow is designed to handle orchestration of data pipelines in batches.
Astronomer recommends to combine these two open source tools by handling low-latency processes with Kafka and data orchestration with Airflow.
Common patterns include:
- Configuring a Kafka cluster with a blob storage like S3 as a sink. Batch process data from S3 at regular intervals.
- Using the ProduceToTopicOperator in Airflow to produce messages to a Kafka cluster as one of several producers.
- Consuming data from a Kafka cluster via the ConsumeFromTopicOperator in batches using the apply function to extract and load information to a blob storage or data warehouse.
- Listening for specific messages in a data stream running through a Kafka cluster using the AwaitMessageTriggerFunctionSensor to trigger downstream tasks after the message appears.
Conclusion
Congratulations! You used the Kafka Airflow provider to directly interact with a Kafka topic from within Apache Airflow.