Orchestrate dbt Core jobs with Airflow and Cosmos
 dbt Core is an open-source library for analytics engineering that helps users build interdependent SQL models for in-warehouse data transformation, using ephemeral compute of data warehouses.
dbt Core is an open-source library for analytics engineering that helps users build interdependent SQL models for in-warehouse data transformation, using ephemeral compute of data warehouses.
dbt on Airflow with Cosmos and the Astro CLI
The open-source provider package Cosmos allows you to integrate dbt jobs into Airflow by automatically creating Airflow tasks from dbt models. You can turn your dbt Core projects into an Airflow task group with just a few lines of code.
Astro supports direct deployment of dbt projects using the Astro CLI. With a single command, you can deploy any valid dbt project to an Astro Deployment. For more information, see Deploy dbt projects to Astro.
There are multiple resources for learning about this topic. See also:
- Webinar: Introducing Cosmos: The Easy Way to Run dbt Models in Airflow.
- Use case: ELT with Airflow and dbt Core including a a ready-to-use example Cosmos project repository.
For a tutorial on how to use dbt Cloud with Airflow, see Orchestrate dbt Cloud with Airflow.
Why use Airflow with dbt Core?
dbt Core offers the possibility to build modular, reuseable SQL components with built-in dependency management and incremental builds.
With Cosmos, you can integrate dbt jobs into your open-source Airflow orchestration environment as standalone DAGs or as task groups within DAGs.
The benefits of using Airflow with dbt Core include:
- Use Airflow's data-aware scheduling and Airflow sensors to run models depending on other events in your data ecosystem.
- Turn each dbt model into a task, complete with Airflow features like retries and error notifications, as well as full observability into past runs directly in the Airflow UI.
- Run
dbt teston tables created by individual models immediately after a model has completed. Catch issues before moving downstream and integrate additional data quality checks with your preferred tool to run alongside dbt tests. - Run dbt projects using Airflow connections instead of dbt profiles. You can store all your connections in one place, directly within Airflow or by using a secrets backend.
- Leverage native support for installing and running dbt in a virtual environment to avoid dependency conflicts with Airflow.
With Astro, you get all the above benefits without having to modify your Airflow environment or create connections. You can deploy directly from a dbt project using the Astro CLI. For more information, see Deploy dbt projects to Astro.
Time to complete
This tutorial takes approximately 30 minutes to complete.
Assumed knowledge
To get the most out of this tutorial, make sure you have an understanding of:
- The basics of dbt Core. See What is dbt?.
- Airflow fundamentals, such as writing DAGs and defining tasks. See Get started with Apache Airflow.
- How Airflow and dbt concepts relate to each other. See Similar dbt & Airflow concepts.
- Airflow operators. See Operators 101.
- Airflow task groups. See Airflow task groups.
- Airflow connections. See Manage connections in Apache Airflow.
Prerequisites
- The Astro CLI.
- Access to a data warehouse supported by dbt Core. See dbt documentation for all supported warehouses. This tutorial uses a Postgres database.
You do not need to have dbt Core installed locally in order to complete this tutorial.
Step 1: Configure your Astro project
To use dbt with Airflow install dbt Core in a virtual environment and Cosmos in a new Astro project.
-
Create a new Astro project:
$ mkdir astro-dbt-core-tutorial && cd astro-dbt-core-tutorial
$ astro dev init -
Open the
Dockerfileand add the following lines to the end of the file:# replace dbt-postgres with another supported adapter if you're using a different warehouse type
RUN python -m venv dbt_venv && source dbt_venv/bin/activate && \
pip install --no-cache-dir dbt-postgres && deactivateThis code runs a bash command when the Docker image is built that creates a virtual environment called
dbt_venvinside of the Astro CLI scheduler container. Thedbt-postgrespackage, which also containsdbt-core, is installed in the virtual environment. If you are using a different data warehouse, replacedbt-postgreswith the adapter package for your data warehouse. -
Add Cosmos and the Postgres provider to your Astro project
requirements.txtfile. If you are using a different data warehouse, replaceapache-airflow-providers-postgreswith the provider package for your data warehouse. You can find information on all provider packages on the Astronomer registry.astronomer-cosmos==1.0.4
apache-airflow-providers-postgres==5.6.0
Step 2: Prepare your dbt project
To integrate your dbt project with Airflow, you need to add the project folder to your Airflow environment. For this step you can either add your own project in a new dbt folder in your dags directory, or follow the steps below to create a simple project using two models.
-
Create a folder called
dbtin yourdagsfolder. -
In the
dbtfolder, create a folder calledmy_simple_dbt_project. -
In the
my_simple_dbt_projectfolder add yourdbt_project.yml. This configuration file needs to contain at least the name of the project. This tutorial additionally shows how to inject a variable calledmy_namefrom Airflow into your dbt project.name: 'my_simple_dbt_project'
vars:
my_name: "No entry" -
Add your dbt models in a subfolder called
modelsin themy_simple_dbt_projectfolder. You can add as many models as you want to run. This tutorial uses the following two models:model1.sql:SELECT '{{ var("my_name") }}' as namemodel2.sql:SELECT * FROM {{ ref('model1') }}model1.sqlselects the variablemy_name.model2.sqldepends onmodel1.sqland selects everything from the upstream model.
You should now have the following structure within your Airflow environment:
.
└── dags
└── dbt
└── my_simple_dbt_project
├── dbt_project.yml
└── models
├── model1.sql
└── model2.sql
Step 3: Create an Airflow connection to your data warehouse
Cosmos allows you to apply Airflow connections to your dbt project.
-
Start Airflow by running
astro dev start. -
In the Airflow UI, go to Admin -> Connections and click +.
-
Create a new connection named
db_conn. Select the connection type and supplied parameters based on the data warehouse you are using. For a Postgres connection, enter the following information:- Connection ID:
db_conn. - Connection Type:
Postgres. - Host: Your Postgres host address.
- Schema: Your Postgres database.
- Login: Your Postgres login username.
- Password: Your Postgres password.
- Port: Your Postgres port.
- Connection ID:
If a connection type for your database isn't available, you might need to make it available by adding the relevant provider package to requirements.txt and running astro dev restart.
Step 4: Write your Airflow DAG
The DAG you'll write uses Cosmos to create tasks from existing dbt models and the PostgresOperator to query a table that was created. You can add more upstream and downstream tasks to embed the dbt project within other actions in your data ecosystem.
-
In your
dagsfolder, create a file calledmy_simple_dbt_dag.py. -
Copy and paste the following DAG code into the file:
"""
### Run a dbt Core project as a task group with Cosmos
Simple DAG showing how to run a dbt project as a task group, using
an Airflow connection and injecting a variable into the dbt project.
"""
from airflow.decorators import dag
from airflow.providers.postgres.operators.postgres import PostgresOperator
from cosmos import DbtTaskGroup, ProjectConfig, ProfileConfig, ExecutionConfig
# adjust for other database types
from cosmos.profiles import PostgresUserPasswordProfileMapping
from pendulum import datetime
import os
YOUR_NAME = "<your_name>"
CONNECTION_ID = "db_conn"
DB_NAME = "<your_db_name>"
SCHEMA_NAME = "<your_schema_name>"
MODEL_TO_QUERY = "model2"
# The path to the dbt project
DBT_PROJECT_PATH = f"{os.environ['AIRFLOW_HOME']}/dags/dbt/my_simple_dbt_project"
# The path where Cosmos will find the dbt executable
# in the virtual environment created in the Dockerfile
DBT_EXECUTABLE_PATH = f"{os.environ['AIRFLOW_HOME']}/dbt_venv/bin/dbt"
profile_config = ProfileConfig(
profile_name="default",
target_name="dev",
profile_mapping=PostgresUserPasswordProfileMapping(
conn_id=CONNECTION_ID,
profile_args={"schema": SCHEMA_NAME},
),
)
execution_config = ExecutionConfig(
dbt_executable_path=DBT_EXECUTABLE_PATH,
)
@dag(
start_date=datetime(2023, 8, 1),
schedule=None,
catchup=False,
params={"my_name": YOUR_NAME},
)
def my_simple_dbt_dag():
transform_data = DbtTaskGroup(
group_id="transform_data",
project_config=ProjectConfig(DBT_PROJECT_PATH),
profile_config=profile_config,
execution_config=execution_config,
operator_args={
"vars": '{"my_name": {{ params.my_name }} }',
},
default_args={"retries": 2},
)
query_table = PostgresOperator(
task_id="query_table",
postgres_conn_id=CONNECTION_ID,
sql=f"SELECT * FROM {DB_NAME}.{SCHEMA_NAME}.{MODEL_TO_QUERY}",
)
transform_data >> query_table
my_simple_dbt_dag()This DAG uses the
DbtTaskGroupclass from the Cosmos package to create a task group from the models in your dbt project. Dependencies between your dbt models are automatically turned into dependencies between Airflow tasks. Make sure to add your own values forYOUR_NAME,DB_NAME, andSCHEMA_NAME.Using the
varskeyword in the dictionary provided to theoperator_argsparameter, you can inject variables into the dbt project. This DAG injectsYOUR_NAMEfor themy_namevariable. If your dbt project contains dbt tests, they will be run directly after a model has completed. Note that it is a best practice to setretriesto at least 2 for all tasks that run dbt models.
In some cases, especially in larger dbt projects, you might run into a DagBag import timeout error.
This error can be resolved by increasing the value of the Airflow configuration core.dagbag_import_timeout.
-
Run the DAG manually by clicking the play button and view the DAG in the graph view. Double click the task groups in order to expand them and see all tasks.
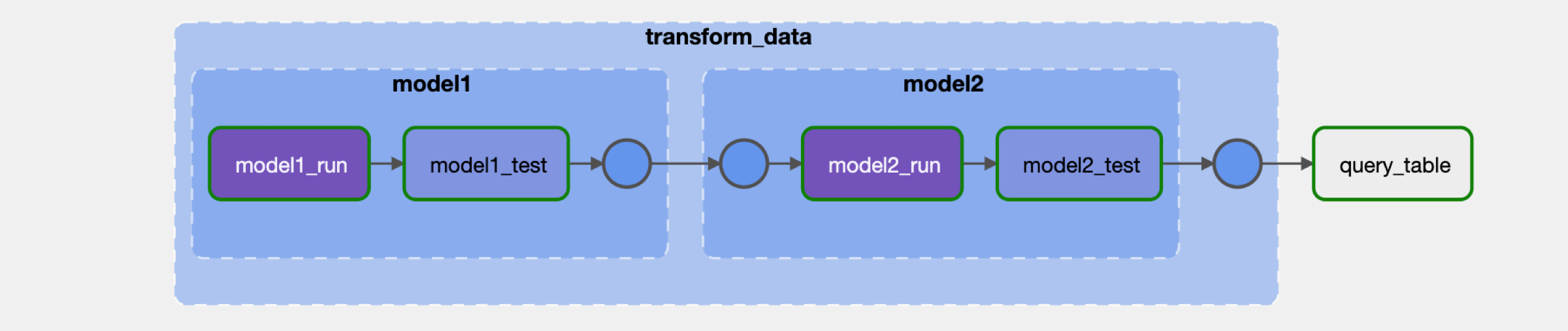
-
Check the XCom returned by the
query_tabletask to see your name in themodel2table.
The DbtTaskGroup class populates an Airflow task group with Airflow tasks created from dbt models inside of a normal DAG. To directly define a full DAG containing only dbt models use the DbtDag class, as shown in the Cosmos documentation.
Congratulations! You've run a DAG using Cosmos to automatically create tasks from dbt models. You can learn more about how to configure Cosmos in the Cosmos documentation.
Alternative ways to run dbt Core with Airflow
While using Cosmos is recommended, there are several other ways to run dbt Core with Airflow.
Using the BashOperator
You can use the BashOperator to execute specific dbt commands. It's recommended to run dbt-core and the dbt adapter for your database in a virtual environment because there often are dependency conflicts between dbt and other packages.
The DAG below uses the BashOperator to activate the virtual environment and execute dbt_run for a dbt project.
from pendulum import datetime
from airflow.decorators import dag
from airflow.operators.bash import BashOperator
PATH_TO_DBT_PROJECT = "<path to your dbt project>"
PATH_TO_DBT_VENV = "<path to your venv activate binary>"
@dag(
start_date=datetime(2023, 3, 23),
schedule="@daily",
catchup=False,
)
def simple_dbt_dag():
dbt_run = BashOperator(
task_id="dbt_run",
bash_command="source $PATH_TO_DBT_VENV && dbt run --models .",
env={"PATH_TO_DBT_VENV": PATH_TO_DBT_VENV},
cwd=PATH_TO_DBT_PROJECT,
)
simple_dbt_dag()
Using the BashOperator to run dbt run and other dbt commands can be useful during development. However, running dbt at the project level has a couple of issues:
- There is low observability into what execution state the project is in.
- Failures are absolute and require all models in a project to be run again, which can be costly.
Using a manifest file
Using a dbt-generated manifest.json file gives you more visibility into the steps dbt is running in each task. This file is generated in the target directory of your dbt project and contains its full representation. For more information on this file, see the dbt documentation.
You can learn more about a manifest-based dbt and Airflow project structure, view example code, and read about the DbtDagParser in a 3-part blog post series on Building a Scalable Analytics Architecture With Airflow and dbt.