Orchestrate pgvector operations with Apache Airflow
Pgvector is an open source extension for PostgreSQL databases that adds the possibility to store and query high-dimensional object embeddings. The pgvector Airflow provider offers modules to easily integrate pgvector with Airflow.
In this tutorial, you use Airflow to orchestrate the embedding of book descriptions with the OpenAI API, ingest the embeddings into a PostgreSQL database with pgvector installed, and query the database for books that match a user-provided mood.
Why use Airflow with pgvector?
Pgvector allows you to store objects alongside their vector embeddings and to query these objects based on their similarity. Vector embeddings are key components of many modern machine learning models such as LLMs or ResNet.
Integrating PostgreSQL with pgvector and Airflow into one end-to-end machine learning pipeline allows you to:
- Use Airflow's data-driven scheduling to run operations involving vectors stored in PostgreSQL based on upstream events in your data ecosystem, such as when a new model is trained or a new dataset is available.
- Run dynamic queries based on upstream events in your data ecosystem or user input via Airflow params on vectors stored in PostgreSQL to retrieve similar objects.
- Add Airflow features like retries and alerts to your pgvector operations.
- Check your vector database for the existence of a unique key before running potentially costly embedding operations on your data.
Time to complete
This tutorial takes approximately 30 minutes to complete (reading your suggested book not included).
Assumed knowledge
To get the most out of this tutorial, make sure you have an understanding of:
- The basics of pgvector. See the README of the pgvector repository.
- Basic SQL. See SQL Tutorial.
- Vector embeddings. See Vector Embeddings.
- Airflow fundamentals, such as writing DAGs and defining tasks. See Get started with Apache Airflow.
- Airflow decorators. Introduction to the TaskFlow API and Airflow decorators.
- Airflow connections. See Managing your Connections in Apache Airflow.
Prerequisites
- The Astro CLI.
- An OpenAI API key of at least tier 1 if you want to use OpenAI for vectorization. If you do not want to use OpenAI, you can adapt the
create_embeddingsfunction at the start of the DAG to use a different vectorizer.
This tutorial uses a local PostgreSQL database created as a Docker container. The image comes with pgvector preinstalled.
The example code from this tutorial is also available on GitHub.
Step 1: Configure your Astro project
-
Create a new Astro project:
$ mkdir astro-pgvector-tutorial && cd astro-pgvector-tutorial
$ astro dev init -
Add the following two packages to your
requirements.txtfile to install the pgvector Airflow provider and the OpenAI Python client in your Astro project:apache-airflow-providers-pgvector==1.0.0
openai==1.3.2 -
This tutorial uses a local PostgreSQL database running in a Docker container. To add a second PostgreSQL container to your Astro project, create a new file in your project's root directory called
docker-compose.override.ymland add the following. Theankane/pgvectorimage builds a PostgreSQL database with pgvector preinstalled.version: '3.1'
services:
postgres_pgvector:
image: ankane/pgvector
volumes:
- ${PWD}/include/postgres:/var/lib/postgresql/data
- ${PWD}/include:/include
networks:
- airflow
ports:
- 5433:5432
environment:
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=postgres
# Airflow containers
scheduler:
networks:
- airflow
webserver:
networks:
- airflow
triggerer:
networks:
- airflow
postgres:
networks:
- airflow -
To create an Airflow connection to the PostgreSQL database, add the following to your
.envfile. If you are using the OpenAI API for embeddings you will need to update theOPENAI_API_KEYenvironment variable.AIRFLOW_CONN_POSTGRES_DEFAULT='{
"conn_type": "postgres",
"login": "postgres",
"password": "postgres",
"host": "host.docker.internal",
"port": 5433,
"schema": "postgres"
}'
OPENAI_API_KEY="<your-openai-api-key>"
Step 2: Add your data
The DAG in this tutorial runs a query on vectorized book descriptions from Goodreads, but you can adjust the DAG to use any data you want.
-
Create a new file called
book_data.txtin theincludedirectory. -
Copy the book description from the book_data.txt file in Astronomer's GitHub for a list of great books.
If you want to add your own books make sure the data is in the following format:
<index integer> ::: <title> (<year of publication>) ::: <author> ::: <description>
One book corresponds to one line in the file.
Step 3: Create your DAG
-
In your
dagsfolder, create a file calledquery_book_vectors.py. -
Copy the following code into the file. If you want to use a vectorizer other than OpenAI, make sure to adjust both the
create_embeddingsfunction at the start of the DAG and provide the correctMODEL_VECTOR_LENGTH."""
## Vectorize book descriptions with OpenAI and store them in Postgres with pgvector
This DAG shows how to use the OpenAI API 1.0+ to vectorize book descriptions and
store them in Postgres with the pgvector extension.
It will also help you pick your next book to read based on a mood you describe.
You will need to set the following environment variables:
- `AIRFLOW_CONN_POSTGRES_DEFAULT`: an Airflow connection to your Postgres database
that has pgvector installed
- `OPENAI_API_KEY`: your OpenAI API key
"""
from airflow.decorators import dag, task
from airflow.models.baseoperator import chain
from airflow.models.param import Param
from airflow.providers.pgvector.operators.pgvector import PgVectorIngestOperator
from airflow.providers.postgres.operators.postgres import PostgresOperator
from airflow.exceptions import AirflowSkipException
from pendulum import datetime
from openai import OpenAI
import uuid
import re
import os
POSTGRES_CONN_ID = "postgres_default"
TEXT_FILE_PATH = "include/book_data.txt"
TABLE_NAME = "Book"
OPENAI_MODEL = "text-embedding-ada-002"
MODEL_VECTOR_LENGTH = 1536
def create_embeddings(text: str, model: str):
"""Create embeddings for a text with the OpenAI API."""
client = OpenAI(api_key=os.environ["OPENAI_API_KEY"])
response = client.embeddings.create(input=text, model=model)
embeddings = response.data[0].embedding
return embeddings
@dag(
start_date=datetime(2023, 9, 1),
schedule=None,
catchup=False,
tags=["pgvector"],
params={
"book_mood": Param(
"A philosophical book about consciousness.",
type="string",
description="Describe the kind of book you want to read.",
),
},
)
def query_book_vectors():
enable_vector_extension_if_not_exists = PostgresOperator(
task_id="enable_vector_extension_if_not_exists",
postgres_conn_id=POSTGRES_CONN_ID,
sql="CREATE EXTENSION IF NOT EXISTS vector;",
)
create_table_if_not_exists = PostgresOperator(
task_id="create_table_if_not_exists",
postgres_conn_id=POSTGRES_CONN_ID,
sql=f"""
CREATE TABLE IF NOT EXISTS {TABLE_NAME} (
book_id UUID PRIMARY KEY,
title TEXT,
year INTEGER,
author TEXT,
description TEXT,
vector VECTOR(%(vector_length)s)
);
""",
parameters={"vector_length": MODEL_VECTOR_LENGTH},
)
get_already_imported_book_ids = PostgresOperator(
task_id="get_already_imported_book_ids",
postgres_conn_id=POSTGRES_CONN_ID,
sql=f"""
SELECT book_id
FROM {TABLE_NAME};
""",
)
@task
def import_book_data(text_file_path: str, table_name: str) -> list:
"Read the text file and create a list of dicts from the book information."
with open(text_file_path, "r") as f:
lines = f.readlines()
num_skipped_lines = 0
list_of_params = []
for line in lines:
parts = line.split(":::")
title_year = parts[1].strip()
match = re.match(r"(.+) \((\d{4})\)", title_year)
try:
title, year = match.groups()
year = int(year)
# skip malformed lines
except:
num_skipped_lines += 1
continue
author = parts[2].strip()
description = parts[3].strip()
list_of_params.append(
{
"book_id": str(
uuid.uuid5(
name=" ".join([title, str(year), author, description]),
namespace=uuid.NAMESPACE_DNS,
)
),
"title": title,
"year": year,
"author": author,
"description": description,
}
)
print(
f"Created a list with {len(list_of_params)} elements "
" while skipping {num_skipped_lines} lines."
)
return list_of_params
@task
def create_embeddings_book_data(
book_data: dict, model: str, already_imported_books: list
) -> dict:
"Create embeddings for a book description and add them to the book data."
already_imported_books_ids = [x[0] for x in already_imported_books]
if book_data["book_id"] in already_imported_books_ids:
raise AirflowSkipException("Book already imported.")
embeddings = create_embeddings(text=book_data["description"], model=model)
book_data["vector"] = embeddings
return book_data
@task
def create_embeddings_query(model: str, **context) -> list:
"Create embeddings for the user provided book mood."
query = context["params"]["book_mood"]
embeddings = create_embeddings(text=query, model=model)
return embeddings
book_data = import_book_data(text_file_path=TEXT_FILE_PATH, table_name=TABLE_NAME)
book_embeddings = create_embeddings_book_data.partial(
model=OPENAI_MODEL,
already_imported_books=get_already_imported_book_ids.output,
).expand(book_data=book_data)
query_vector = create_embeddings_query(model=OPENAI_MODEL)
import_embeddings_to_pgvector = PgVectorIngestOperator.partial(
task_id="import_embeddings_to_pgvector",
trigger_rule="none_failed",
conn_id=POSTGRES_CONN_ID,
sql=(
f"INSERT INTO {TABLE_NAME} "
"(book_id, title, year, author, description, vector) "
"VALUES (%(book_id)s, %(title)s, %(year)s, "
"%(author)s, %(description)s, %(vector)s) "
"ON CONFLICT (book_id) DO NOTHING;"
),
).expand(parameters=book_embeddings)
get_a_book_suggestion = PostgresOperator(
task_id="get_a_book_suggestion",
postgres_conn_id=POSTGRES_CONN_ID,
trigger_rule="none_failed",
sql=f"""
SELECT title, year, author, description
FROM {TABLE_NAME}
ORDER BY vector <-> CAST(%(query_vector)s AS VECTOR)
LIMIT 1;
""",
parameters={"query_vector": query_vector},
)
@task
def print_suggestion(query_result, **context):
"Print the book suggestion."
query = context["params"]["book_mood"]
book_title = query_result[0][0]
book_year = query_result[0][1]
book_author = query_result[0][2]
book_description = query_result[0][3]
print(f"Book suggestion for '{query}':")
print(
f"You should read {book_title} by {book_author}, published in {book_year}!"
)
print(f"Goodreads describes the book as: {book_description}")
chain(
enable_vector_extension_if_not_exists,
create_table_if_not_exists,
get_already_imported_book_ids,
import_embeddings_to_pgvector,
get_a_book_suggestion,
print_suggestion(query_result=get_a_book_suggestion.output),
)
chain(query_vector, get_a_book_suggestion)
chain(get_already_imported_book_ids, book_embeddings)
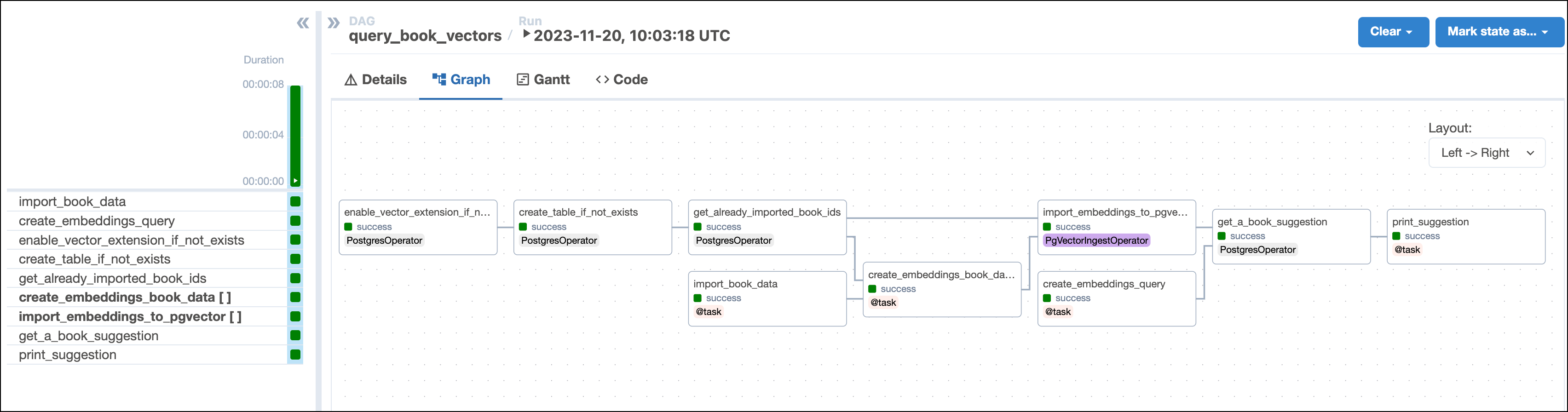
query_book_vectors()This DAG consists of nine tasks to make a simple ML orchestration pipeline.
- The
enable_vector_extension_if_not_existstask uses a PostgresOperator to enable the pgvector extension in the PostgreSQL database. - The
create_table_if_not_existstask creates theBooktable in PostgreSQL. Note theVECTOR()datatype used for thevectorcolumn. This datatype is added to PostgreSQL by the pgvector extension and needs to be defined with the vector length of the vectorizer you use as an argument. This example uses the OpenAI'stext-embedding-ada-002to create 1536-dimensional vectors, so we define the columns with the typeVECTOR(1536)using parameterized SQL. - The
get_already_imported_book_idstask queries theBooktable to return allbook_idvalues of books that were already stored with their vectors in previous DAG runs. - The
import_book_datatask uses the@taskdecorator to read the book data from thebook_data.txtfile and return it as a list of dictionaries with keys corresponding to the columns of theBooktable. - The
create_embeddings_book_datatask is dynamically mapped over the list of dictionaries returned by theimport_book_datatask to parallelize vector embedding of all book descriptions that have not been added to theBooktable in previous DAG runs. Thecreate_embeddingsfunction defines how the embeddings are computed and can be modified to use other embedding models. If all books in the list have already been added to theBooktable, then all mapped task instances are skipped. - The
create_embeddings_querytask applies the samecreate_embeddingsfunction to the desired book mood the user provided via Airflow params. - The
import_embeddings_to_pgvectortask uses the PgVectorIngestOperator to insert the book data including the embedding vectors into the PostgreSQL database. This task is dynamically mapped to import the embeddings from one book at a time. The dynamically mapped task instances of books that have already been imported in previous DAG runs are skipped. - The
get_a_book_suggestiontask queries the PostgreSQL database for the book that is most similar to the user-provided mood using nearest neighbor search. Note how the vector of the user-provided book mood (query_vector) is cast to theVECTORdatatype before similarity search:ORDER BY vector <-> CAST(%(query_vector)s AS VECTOR). - The
print_book_suggestiontask prints the book suggestion to the task logs.
- The
For information on more advanced search techniques in pgvector, see the pgvector README.
Step 4: Run your DAG
-
Run
astro dev startin your Astro project to start Airflow and open the Airflow UI atlocalhost:8080. -
In the Airflow UI, run the
query_book_vectorsDAG by clicking the play button. Then, provide the Airflow param for the desiredbook_mood.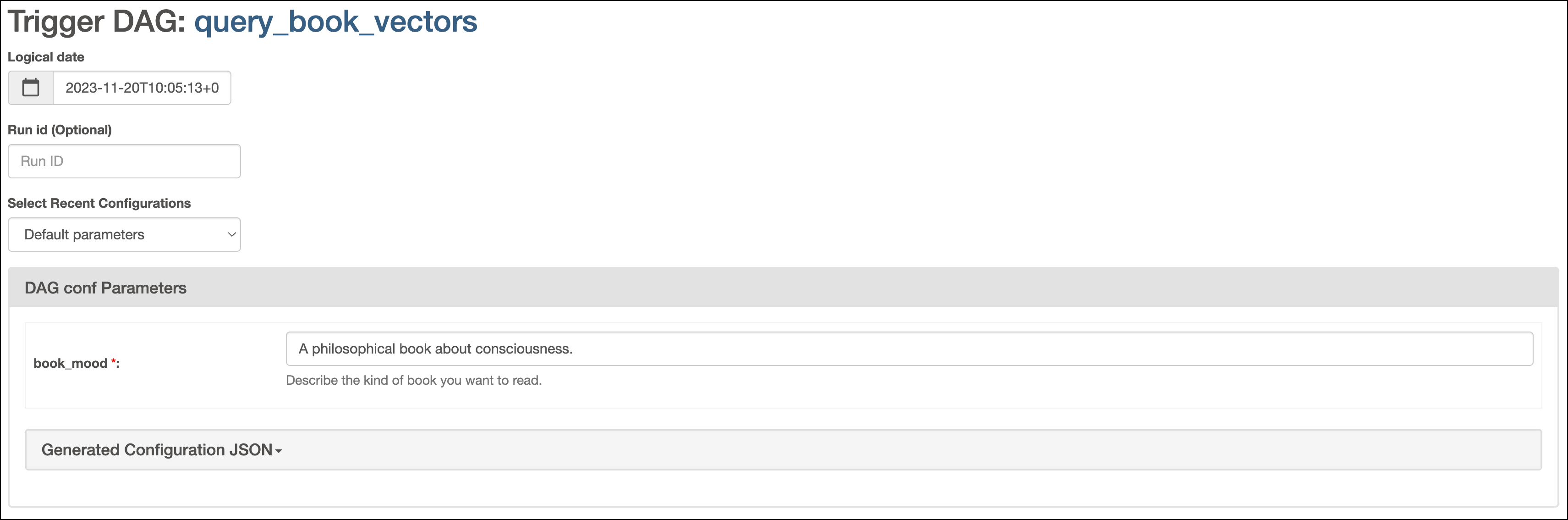
-
View your book suggestion in the task logs of the
print_book_suggestiontask:[2023-11-20, 10:09:43 UTC] {logging_mixin.py:154} INFO - Book suggestion for 'A philosophical book about consciousness.':
[2023-11-20, 10:09:43 UTC] {logging_mixin.py:154} INFO - You should read The Idea of the World by Bernardo Kastrup, published in 2019!
[2023-11-20, 10:09:43 UTC] {logging_mixin.py:154} INFO - Goodreads describes the book as: A rigorous case for the primacy of mind in nature, from philosophy to neuroscience, psychology and physics. [...]
Step 5: (Optional) Fetch and read the book
- Go to the website of your local library and search for the book. If it is available, order it and wait for it to arrive. You will likely need a library card to check out the book.
- Make sure to prepare an adequate amount of tea for your reading session. Astronomer recommends Earl Grey, but you can use any tea you like.
- Enjoy your book!
Conclusion
Congratulations! You used Airflow and pgvector to get a book suggestion! You can now use Airflow to orchestrate pgvector operations in your own machine learning pipelines. Additionally, you remembered the satisfaction and joy of spending hours reading a good book and supported your local library.