Astro Cloud IDE quickstart
Use this quickstart to create and run your first project with the Cloud IDE.
Time to complete
This quickstart takes approximately 30 minutes to complete.
Prerequisites
To complete this quickstart, you need:
-
Workspace Operator permissions in an Astro Workspace.
-
Optional. A database hosted in one of the following services:
- GCP BigQuery
- Postgres (hosted)
- Snowflake
- AWS S3
- Redshift
If you don't provide a database, you can still complete the quickstart. However, you won't be able to test SQL code in your pipeline.
Step 1: Log in and create a project
The Cloud IDE is available to all Astro customers and can be accessed in the Astro UI.
- Log in to the Astro UI and select a Workspace.
- Click Cloud IDE in the left menu. If you are the first person in your Workspace to use the Astro Cloud IDE, the Projects page is empty.
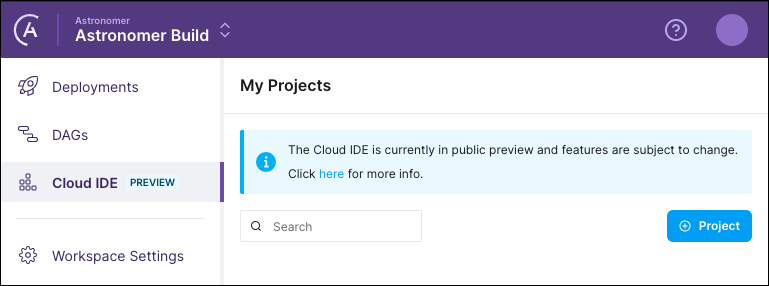
- Click + Project, enter a name and a description for the project, and then click Create.
After you create your project, the Cloud IDE opens your project home page with the following tabs:
- The Pipelines tab stores all of the Python and SQL code that your project executes.
- The Connections tab stores Airflow connections for connecting your project to external services.
- The Variables tab stores Airflow variables used in your pipeline code.
- The Requirements tab stores the required Python and OS-level dependencies for running your pipelines.
Step 2: Create a pipeline
-
Click the Pipelines tab and then click + Pipeline.
-
Enter a name and a description for the pipeline and then click Create.
When you first run your project, your pipeline is built into a single DAG with the name you provide. Because of this, pipeline names must be unique within their project. They must also be a Python identifier, so they can't contain spaces or special characters.
After clicking Create, the IDE opens the pipeline editor. This is where you'll write your pipeline code.
Step 3: Create a Python cell
Cells are the building blocks for pipelines. They can complete a unit of work, such as a Python function or SQL query, or they can define assets for use throughout your pipeline. For this quickstart, you'll write a Python cell named hello_world.
-
In the Pipeline list, click the name of the pipeline you created in step 2.
-
Click Add Cell and select Python. A new cell named
python_1appears. -
Click the cell's name and rename the cell
hello_world. -
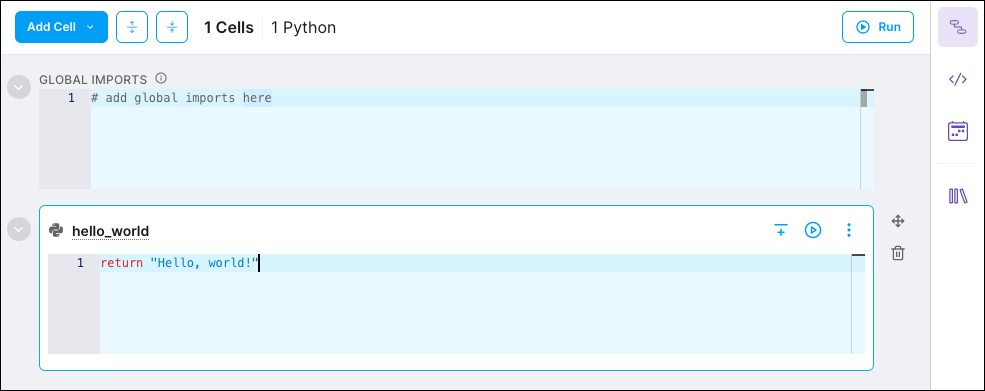
Add the following code to the cell:
return "Hello, world!"
Your pipeline editor should look like the following:
Step 4: Run your cell
In the hello_world cell, click Run to execute a single run of your cell.
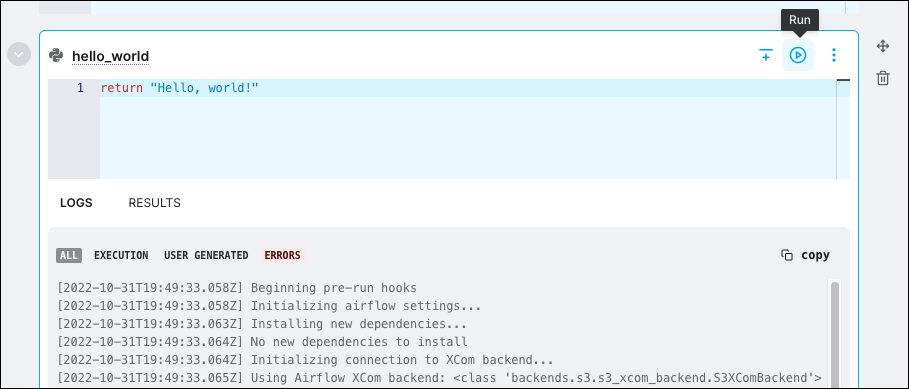
When you run a cell, the Cloud IDE sends a request to an isolated worker in the Astronomer-managed control plane. The worker executes your cell and returns the results to the Cloud IDE. Executing cells in the Cloud IDE is offered free of charge. For more information on execution, see Execution.
The Logs tab contains all logs generated by the cell run, including Airflow logs and Python errors. The Results tab contains the contents of your Python console. Click Results to view the result of your successful cell run.
If the error message Could not connect to cell execution environment appears after running a cell, check the Astro status page to determine the operational status of the Astro control plane. If the control plane is operational, contact Astronomer support and share the error. To enable cell runs, Astronomer support might need to set up additional cloud infrastructure for the IDE.
Step 5: Create a database connection
To create a SQL cell and execute SQL, first create a database to run your SQL queries against.
-
Click the Connections tab and then click Connection.

-
Click NEW CONNECTION.
-
Choose one of the available connection types and configure all required values for the connection. Click More options to configure optional values for the connection.
SQL cell query results are stored in XComs and are not accessible outside of your data pipeline. To save the results of a SQL query, run it in a SQL warehouse cell. See Run SQL.
-
Optional. Click Test Connection. The Astro Cloud IDE runs a quick connection test and returns a status message. You can still create the connection if the test is unsuccessful.
-
Click Create Connection. You new connection appears in the Connections tab both in the pipeline editor and on your project homepage. You can use this connection with any future pipelines you create in this project.
Step 6: Create a SQL cell
You can now write and run SQL cells with your database connection.
-
In the Pipeline list, click the name of the pipeline you created in step 2.
-
Click Add Cell and select SQL. A new cell named
sql_1appears. -
Click the cell name and rename it
hello_sql. -
In the Select Connection list, select the connection you created in step 5.
-
Add the following code to the cell:
SELECT 1 AS hello_world;
You can also add a SQL cell with a specific connection by clicking the + button from the Connections tab in the Environment menu.
- Optional. Click Run to test the SQL query. The results of your query appear in the Results tab.
Step 7: Create dependencies between cells
You now have a Python cell and a SQL cell, but there's no logic to determine which task runs first in your DAG. You can create dependencies for these cells directly in the Astro Cloud IDE.
-
In the
hello_sqlcell, click Dependencies and then selecthello_world.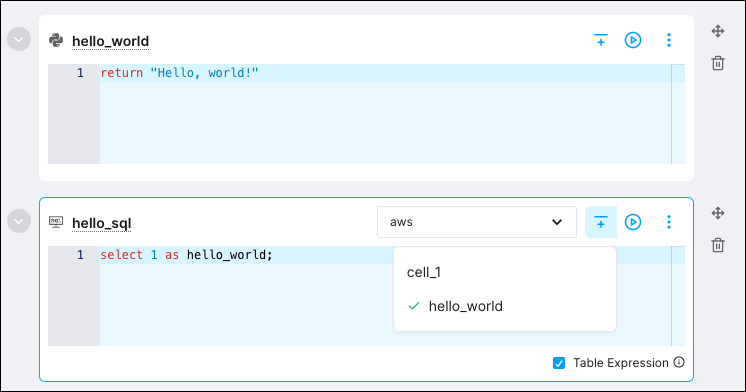
-
To confirm that the dependency was established, click Pipeline. The Pipeline view shows the dependencies between your cells.
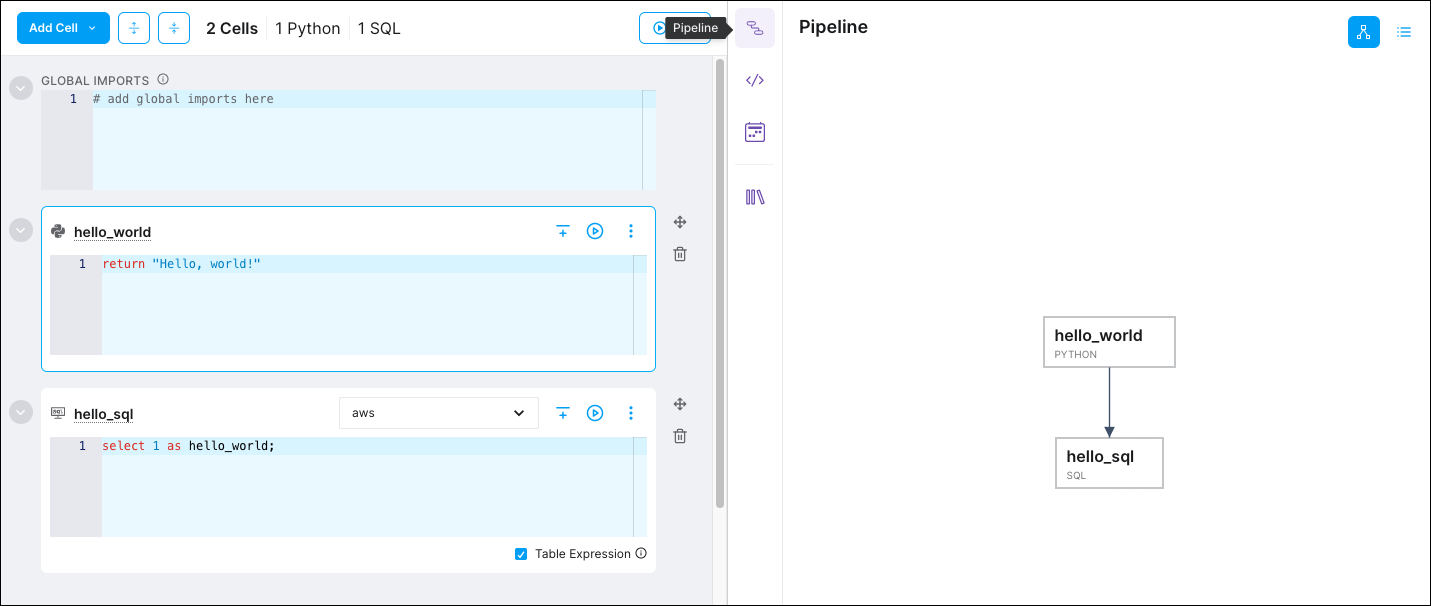
Step 8: Make data references in your code
One of the most powerful features of the Astro Cloud IDE is that it can automatically detect data dependencies in your cell code and restructure your pipeline based on those dependencies. This works for both Python and SQL cells.
To create a potential dependency to a Python cell, the upstream Python cell must end with a return statement. This means that you can create a downstream dependency from hello_world.
-
Create a new Python cell named
data_dependency. -
Add the following code to the cell:
my_string = hello_world
return my_stringYou can pass any value from a
returnstatement into a downstream Python cell by calling the name of the upstream Python cell. -
Click Pipeline to confirm that your dependency graph was updated:
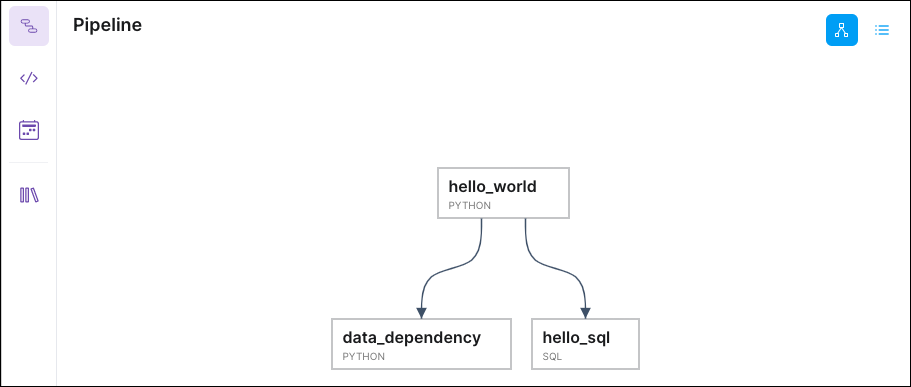
You can generate data dependencies between any two cell types. To learn more about data dependencies, see Pass data between cells.
Step 9: Run your pipeline
Now that you've completed your pipeline, click Run in the top right corner of your pipeline editing window to run it from beginning to end. Cells are executed in order based on their dependencies. During the run, the Pipeline page shows which cells have been executed and which are still pending.
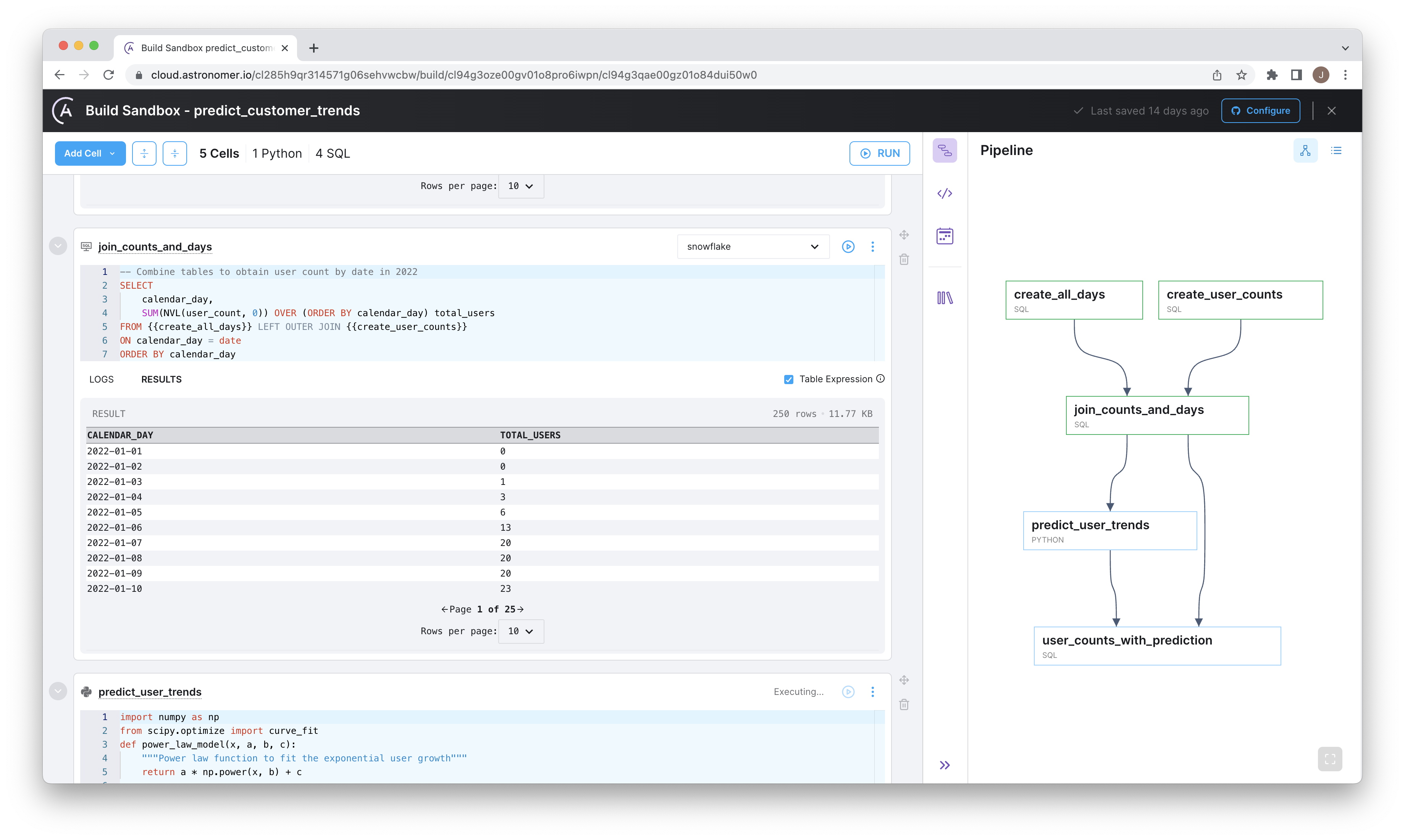
Step 10: Schedule your pipeline
After you've verified that your pipeline is working, you can schedule it to run regularly.
-
To set your pipeline's schedule, click Schedule.
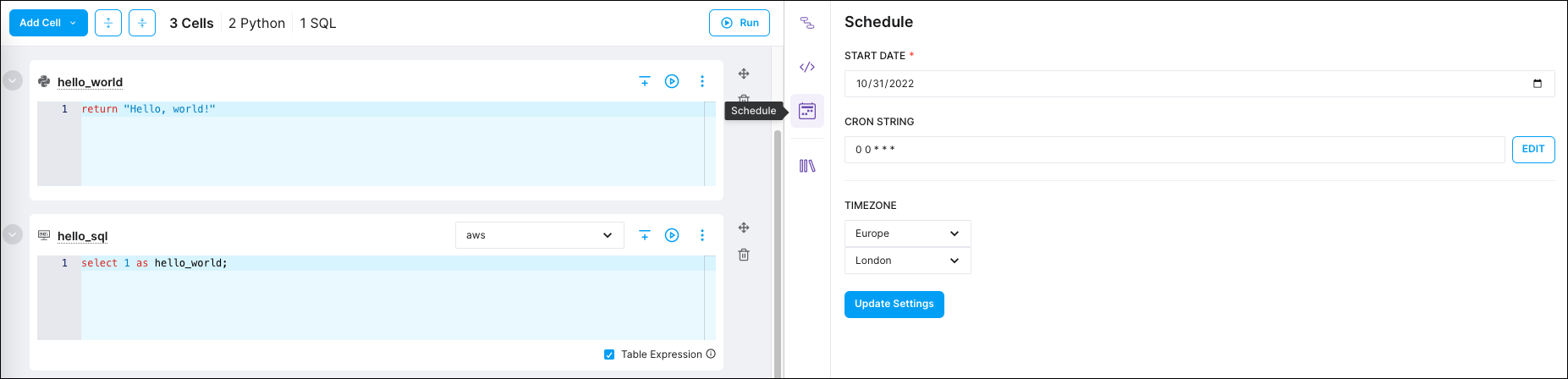
-
Manually enter a cron string, or click EDIT to open the cron builder, which is a simple UI for setting a cron schedule.
-
Make your selections and close the cron builder, the Astro Cloud IDE loads a newly generated cron schedule.
-
Click Update Settings to save your changes.
Configuring your pipeline's schedule will not automatically run it on a scheduled basis. You must deploy your pipeline for it to run. See Deploy a project for setup steps.