ELT with Airflow and dbt Core
 dbt Core is a popular open-source library for analytics engineering that helps users build interdependent SQL models. Thanks to the Cosmos provider package, you can integrate any dbt project into your DAG with only a few lines of code. The open-source Astro Python SDK greatly simplifies common ELT tasks like loading data and allows users to easily use Pandas on data stored in a data warehouse.
dbt Core is a popular open-source library for analytics engineering that helps users build interdependent SQL models. Thanks to the Cosmos provider package, you can integrate any dbt project into your DAG with only a few lines of code. The open-source Astro Python SDK greatly simplifies common ELT tasks like loading data and allows users to easily use Pandas on data stored in a data warehouse.
This example uses a DAG to load data about changes in solar and renewable energy capacity in different European countries from a local CSV file into a data warehouse. Transformation steps in dbt Core filter the data for a country selected by the user and calculate the percentage of solar and renewable energy capacity for that country in different years. Depending on the trajectory of the percentage of solar and renewable energy capacity in the selected country, the DAG will print different messages to the logs.
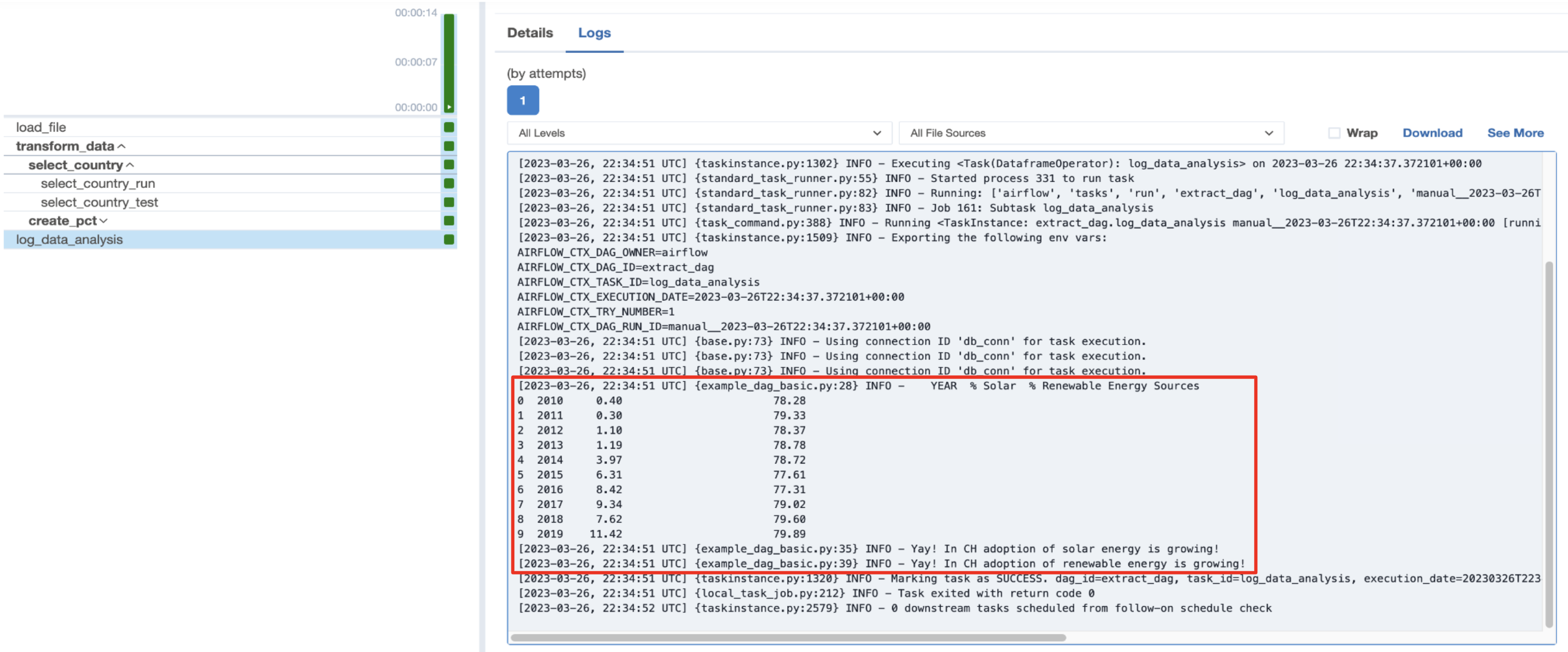
After the DAG in this project runs, the logs of the last task (log_data_analysis) show the proportion of solar and renewable energy capacity development in a country you selected.
For more detailed instructions on using dbt Core with Cosmos, see the dbt Core tutorial.
Before you start
Before trying this example, make sure you have:
- The Astro CLI.
- Docker Desktop.
- Access to a data warehouse supported by dbt Core and the Astro Python SDK. See dbt supported warehouses and Astro Python SDK supported warehouses. This example uses a local PostgreSQL database with a database called
postgresand a schema calledpostgres.
Clone the project
Clone the example project from this Astronomer GitHub. Make sure to create a file called .env with the contents of the .env_example file in the project root directory and replace the connection details with your own.
Run the project
To run the example project, first make sure Docker Desktop is running. Then, navigate to your project directory and run:
astro dev start
This command builds your project and spins up 4 Docker containers on your machine to run it. After the command finishes, open the Airflow UI at https://localhost:8080/ and trigger the my_energy_dag DAG using the play button.
Project contents
Data source
This example analyzes changes in solar and renewable energy capacity in different European countries. The full source data provided by Open Power System Data includes information on many types of energy capacity. The subset of data used in this example can be found in the GitHub repository, and is read by the DAG from the include folder of the Astro project.
Project code
This project consists of one DAG, my_energy_dag, which performs an ELT process using two tasks defined with Astro Python SDK operators and one task group created through Cosmos that orchestrates a dbt project consisting of two models.
First, the full dataset containing solar and renewable energy capacity data for several European cities is loaded into the data warehouse using the Astro Python SDK load file operator. Using the Astro Python SDK in this step allows you to easily switch between data warehouses, simply by changing the connection ID.
load_data = aql.load_file(
input_file=File(CSV_FILEPATH),
output_table=Table(
name="energy",
conn_id=CONNECTION_ID,
metadata=Metadata(
database=DB_NAME,
schema=SCHEMA_NAME,
),
),
)
Then, the transform_data task group is created using the DbtTaskGroup class from Cosmos with a simple ProfileConfig and ExecutionConfig:
profile_config = ProfileConfig(
profile_name="default",
target_name="dev",
profile_mapping=PostgresUserPasswordProfileMapping(
conn_id=CONNECTION_ID,
profile_args={"schema": SCHEMA_NAME},
),
)
execution_config = ExecutionConfig(
dbt_executable_path=DBT_EXECUTABLE_PATH,
)
# ...
dbt_tg = DbtTaskGroup(
group_id="transform_data",
project_config=ProjectConfig(DBT_PROJECT_PATH),
profile_config=profile_config,
execution_config=execution_config,
operator_args={
"vars": '{"country_code": "CH"}',
},
)
The Airflow tasks within the task group are automatically inferred by Cosmos from the dependencies between the two dbt models:
-
The first model,
select_country, queries the table created by the previous task and creates a subset of the data by only selecting rows for the country that was specified as thecountry_codevariable in theoperator_argsparameter of theDbtTaskGroup. See the dataset for all available country codes.select
"YEAR", "COUNTRY", "SOLAR_CAPACITY", "TOTAL_CAPACITY", "RENEWABLES_CAPACITY"
from postgres.postgres.energy
where "COUNTRY" = '{{ var("country_code") }}' -
The second model,
create_pct, divides both the solar and renewable energy capacity by the total energy capacity for each year calculating the fractions of these values. Note how the dbtreffunction creates a dependency between this model and the upstream modelselect_country. Cosmos then automatically translates this into a dependency between Airflow tasks.select
"YEAR", "COUNTRY", "SOLAR_CAPACITY", "TOTAL_CAPACITY", "RENEWABLES_CAPACITY",
"SOLAR_CAPACITY" / "TOTAL_CAPACITY" AS "SOLAR_PCT",
"RENEWABLES_CAPACITY" / "TOTAL_CAPACITY" AS "RENEWABLES_PCT"
from {{ ref('select_country') }}
where "TOTAL_CAPACITY" is not NULL
Finally, the log_data_analysis task uses the Astro Python SDK dataframe operator to run an analysis on the final table and logs the results.
@aql.dataframe
def log_data_analysis(df: pd.DataFrame):
"... code to determine the year with the highest solar and renewable energy capacity ..."
if latest_year == year_with_the_highest_solar_pct:
task_logger.info(
f"Yay! In {df.COUNTRY.unique()[0]} adoption of solar energy is growing!"
)
if latest_year == year_with_the_highest_renewables_pct:
task_logger.info(
f"Yay! In {df.COUNTRY.unique()[0]} adoption of renewable energy is growing!"
)
The files come together in the following project structure:
.
├── dags
│ ├── dbt
│ │ └── my_energy_project
│ │ ├── dbt_project.yml
│ │ └── models
│ │ ├── select_country.sql
│ │ └── create_pct.sql
│ └── my_energy_dag.py
├── include
│ └── subset_energy_capacity.csv
├── Dockerfile
└── requirements.txt
In some cases, especially in larger dbt projects, you might run into a DagBag import timeout error.
This error can be resolved by increasing the value of the Airflow configuration core.dagbag_import_timeout.
See also
- Tutorial: Orchestrate dbt Core jobs with Airflow and Cosmos.
- Documentation: Astronomer Cosmos.
- Webinar: Introducing Cosmos: The Easy Way to Run dbt Models in Airflow.
- Demo: See how to deploy your dbt projects to Astro