Use Cohere and OpenSearch to analyze customer feedback in an MLOps pipeline
With recent advances in the field of Large Language Model Operations (LLMOps), you can now combine the power of different language models to more efficiently get an answer to a query. This use case shows how you can use Apache Airflow to orchestrate an MLOps pipeline using two different models: You'll use embeddings and text classification by Cohere with an OpenSearch search engine to analyze synthetic customer feedback data.

Before you start
Before trying this example, make sure you have:
- The Astro CLI.
- Docker Desktop.
Clone the project
Clone the example project from the Astronomer GitHub. To keep your credentials secure when you deploy this project to your own git repository, create a file called .env with the contents of the .env_example file in the project root directory.
The repository is configured to create and use a local OpenSearch instance, accessible on port 9200. If you already have a cloud-based OpenSearch instance, you can update the value of AIRFLOW_CONN_OPENSEARCH_DEFAULT in .env to connect to your own instance.
To use the Cohere API, you need to create an account and get an API key. A free tier key is sufficient for this example. To use your API key, replace <your-cohere-api-key> in the .env file with your API key value.
Run the project
To run the example project, first make sure Docker is running. Then, open your project directory and run:
astro dev start
This command builds your project and spins up 6 Docker containers on your machine to run it:
- The Airflow webserver, which runs the Airflow UI and can be accessed at
https://localhost:8080/. - The Airflow scheduler, which is responsible for monitoring and triggering tasks.
- The Airflow triggerer, which is an Airflow component used to run deferrable operators.
- The Airflow metadata database, which is a Postgres database that runs on port
5432. - A Python container running a mock API that generates synthetic customer feedback data, accessible at port
5000. - A local OpenSearch instance, running on port
9200.
To run the pipeline, run the analyze_customer_feedback DAG by clicking the Play button. Note that the get_sentiment and get_embeddings tasks can take a few minutes to complete while the Cohere API processes the text. If you want to quickly test the DAG, set the NUM_CUSTOMERS variable at the beginning of the DAG to a lower number.
The other parameters at the beginning of the DAG, such as TESTIMONIAL_SEARCH_TERM or FEEDBACK_SEARCH_TERMS can be adjusted as well to change parts of the OpenSearch queries in the DAG. If you adjust these parameters, make sure to also change the feedback_options in the app.py file of the mock API to create customer feedback that matches your updated search terms.
Project contents
Data source
The data in this example is generated using the app.py script included in the project. The script creates synthetic customer reviews based on a list of examples and a set of randomized customer parameters.
Project overview
This project contains two DAGs, one for the MLOps pipeline and one DAG to delete the index in OpenSearch for testing purposes.
The analyze_customer_feedback DAG ingests data from the mock API and loads it into an OpenSearch index. The DAG then uses the Cohere API to get sentiment scores and embeddings for a subset of the customer feedback returned by a keyword OpenSearch query. The embeddings and sentiment analysis scores are ingested back into OpenSearch and a final query is performed to get the positive feedback most similar to a target testimonial. The DAG ends by printing the retrieved testimonial to the logs.
The delete_opensearch_index DAG deletes the INDEX_TO_DELETE in OpenSearch. This DAG is used during development to allow the analyze_customer_feedback DAG to create the index from scratch. Run this DAG if you would like to start from a clean slate, for example when making changes to the index schema to adapt the project to your own use case.
Project code
This use case showcases how you can use the OpenSearch and Cohere Airflow provider to analyze customer feedback in an MLOps Airflow pipeline.
The tasks in the analyze_customer_feedback DAG can be grouped into four sections:
-
Ingest customer feedback data into OpenSearch
-
Query customer feedback data from OpenSearch
-
Perform sentiment analysis on relevant customer feedback and get embeddings using the Cohere API
-
Query OpenSearch for the most similar testimonial using a k-nearest neighbors (k-NN) algorithm on the embeddings and filter for positive sentiment

Several parameters are set at the beginning of the DAG. You can adjust the number of pieces of customer feedback returned by the mock API by changing the NUM_CUSTOMERS variable.
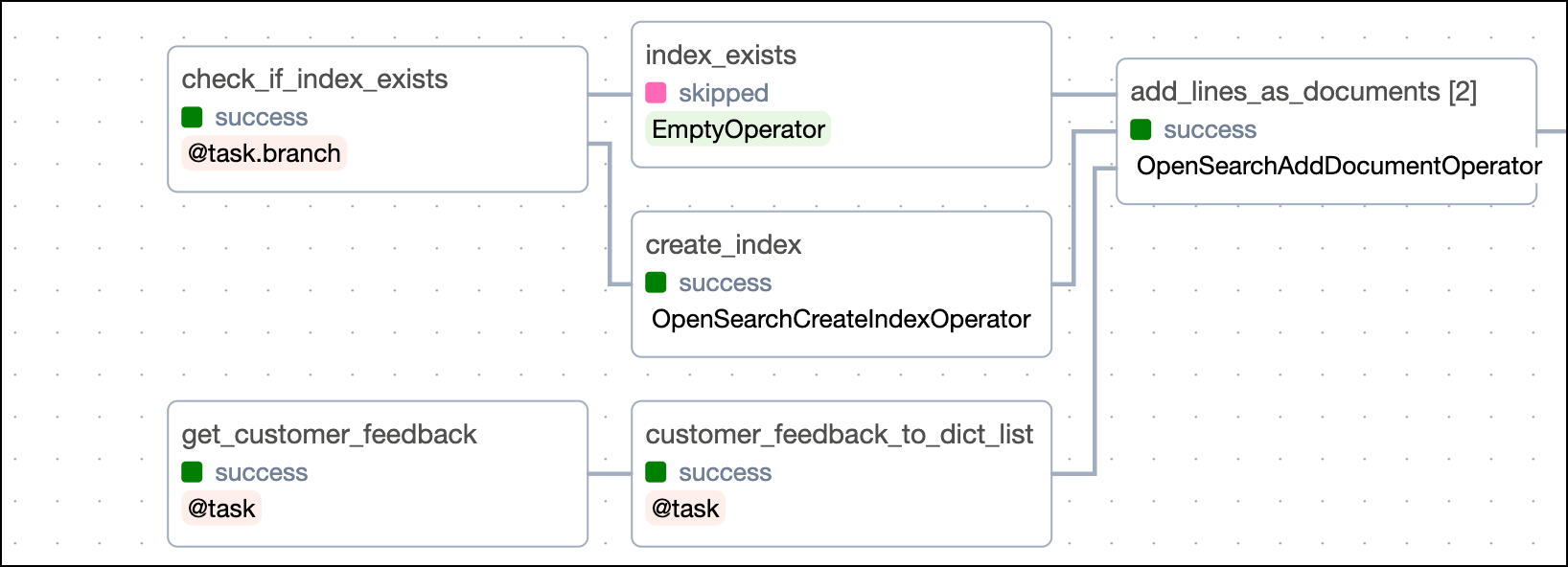
Ingest customer feedback data into OpenSearch
The first six tasks in the analyze_customer_feedback DAG perform the necessary steps to ingest data from the mock API into OpenSearch.
First, the check_if_index_exists task uses the OpenSearchHook to check if an index of the name OPEN_SEARCH_INDEX already exists in your OpenSearch instance. The task is defined using the @task.branch decorator and returns a different task_id depending on the result of the check. If the index already exists, the empty index_exists task will be executed. If the index does not exist, the create_index task will be executed.
@task.branch
def check_if_index_exists(index_name: str, conn_id: str) -> str:
"Check if the index already exists in OpenSearch."
client = OpenSearchHook(open_search_conn_id=conn_id, log_query=True).client
is_index_exist = client.indices.exists(index_name)
if is_index_exist:
return "index_exists"
return "create_index"
The create_index task performs index creation using the OpenSearchCreateIndexOperator. Note how the dictionary passed to the index_body parameter includes the properties of the customer feedback documents, including fields for the embeddings and sentiment scores.
create_index = OpenSearchCreateIndexOperator(
task_id="create_index",
opensearch_conn_id=OPENSEARCH_CONN_ID,
index_name=OPENSEARCH_INDEX_NAME,
index_body={
"settings": {
"index": {
"number_of_shards": 1,
"knn": True,
"knn.algo_param.ef_search": 100,
}
},
"mappings": {
"properties": {
"customer_feedback": {"type": "text"},
"customer_rating": {"type": "integer"},
"customer_id": {"type": "keyword"},
"timestamp": {"type": "date"},
"customer_location": {"type": "keyword"},
"product_type": {"type": "keyword"},
"ab_test_group": {"type": "keyword"},
"embeddings": {
"type": "knn_vector",
"dimension": MODEL_VECTOR_LENGTH,
"method": {
"name": "hnsw",
"space_type": "cosinesimil",
"engine": "nmslib",
},
},
"sentiment_prediction": {"type": "keyword"},
"sentiment_confidence": {"type": "float"},
}
},
},
)
Running in parallel, the get_customer_feedback task makes a call to the mock API exposed at customer_ticket_api:5000.
@task
def get_customer_feedback(num_customers: int) -> list:
"Query the mock API for customer feedback data."
r = requests.get(
f"http://customer_ticket_api:5000/api/data?num_reviews={num_customers}"
)
return r.json()
The payload of the mock API is in the format of:
{
'ab_test_group': 'A',
'customer_feedback': 'This product has transformed the way I work, absolutely fantastic UX!',
'customer_id': 1714,
'customer_location': 'Switzerland',
'customer_rating': 3,
'product_type': 'cloud service A',
'timestamp': '2023-11-24T11:25:37Z'
}
Next, the customer_feedback_to_dict_list task transforms the above payload into a list of dictionaries to be provided to the OpenSearchAddDocumentOperator document and doc_id parameters.
@task
def customer_feedback_to_dict_list(customer_feedback: list):
"Convert the customer feedback data into a list of dictionaries."
list_of_feedback = []
for customer in customer_feedback:
unique_line_id = uuid.uuid5(
name=" ".join(
[str(customer["customer_id"]), str(customer["timestamp"])]
),
namespace=uuid.NAMESPACE_DNS,
)
kwargs = {"doc_id": str(unique_line_id), "document": customer}
list_of_feedback.append(kwargs)
return list_of_feedback
The resulting list of dictionaries takes the form of:
[
{
"doc_id": "9c3880f4-f883-50d2-8a41-056c0efe4b2b",
"document": {
"ab_test_group": "A",
"customer_feedback": "This product has transformed the way I work, absolutely fantastic UX!",
"customer_id": 1714,
"customer_location": "Switzerland",
"customer_rating": 3,
"product_type": "cloud service A",
"timestamp": "2023-11-24T11:25:37Z",
},
},
{
"doc_id": "804dfcfd-62f5-5f8c-b64e-b167dcb4b1dc",
"document": {
"ab_test_group": "A",
"customer_feedback": "The product did not meet my expectations, ugly UI.",
"customer_id": 1843,
"customer_location": "Switzerland",
"customer_rating": 1,
"product_type": "cloud service A",
"timestamp": "2023-11-24T11:25:37Z",
},
},
]
Lastly, the add_lines_as_documents task uses the OpenSearchAddDocumentOperator to add the customer feedback data to the OpenSearch index. This task is dynamically mapped over the list of dictionaries returned by the customer_feedback_to_dict_list task to create one mapped task instance per set of doc_id and document parameter inputs. To map over a list of dictionaries, the .expand_kwargs method is used.
add_lines_as_documents = OpenSearchAddDocumentOperator.partial(
task_id="add_lines_as_documents",
opensearch_conn_id=OPENSEARCH_CONN_ID,
trigger_rule="none_failed",
index_name=OPENSEARCH_INDEX_NAME,
).expand_kwargs(list_of_document_kwargs)
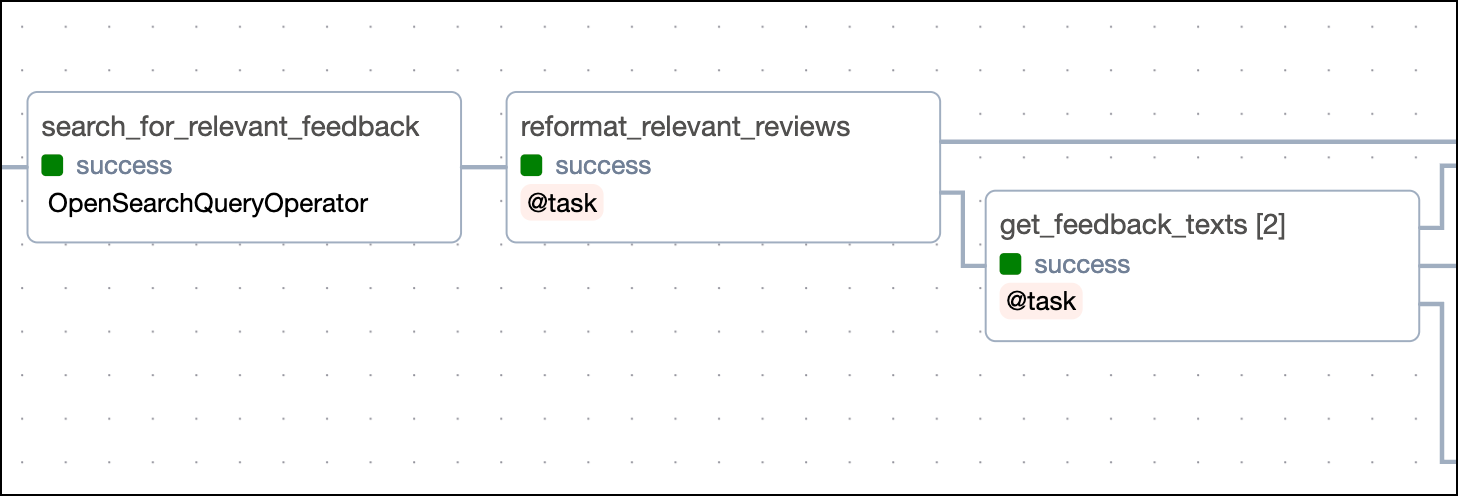
Query customer feedback data from OpenSearch
In the second part of the DAG, OpenSearch is queried to get the subset of customer feedback data we are interested in. For this example, we chose feedback from Swiss customers in the A test group using cloud service A who mentioned the user experience in their feedback.
The search_for_relevant_feedback task uses the OpenSearchQueryOperator to query OpenSearch for the relevant customer feedback data. The query is defined using query domain-specific language (DSL) and passed to the query parameter of the operator. OpenSearch fuzzy matches the terms provided in the FEEDBACK_SEARCH_TERMS variable while filtering for the CUSTOMER_LOCATION, AB_TEST_GROUP, and PRODUCT_TYPE variables.
search_for_relevant_feedback = OpenSearchQueryOperator(
task_id="search_for_relevant_feedback",
opensearch_conn_id=OPENSEARCH_CONN_ID,
index_name=OPENSEARCH_INDEX_NAME,
query={
"size": MAX_NUMBER_OF_RESULTS,
"query": {
"bool": {
"must": [
{
"match": {
"customer_feedback": {
"query": FEEDBACK_SEARCH_TERMS,
"analyzer": "english",
"fuzziness": "AUTO",
}
}
}
],
"filter": [
{"term": {"customer_location": CUSTOMER_LOCATION}},
{"term": {"ab_test_group": AB_TEST_GROUP}},
{"term": {"product_type": PRODUCT_TYPE}},
],
},
},
},
)
The returned customer feedback data is then transformed using the reformat_relevant_reviews task to get a list of dictionaries.
@task
def reformat_relevant_reviews(search_results: dict) -> list:
"Reformat the relevant reviews from the OpenSearch query results."
ids = [x["_id"] for x in search_results["hits"]["hits"]]
reviews_of_interest = [x["_source"] for x in search_results["hits"]["hits"]]
reviews_with_id = []
for id, review in zip(ids, reviews_of_interest):
review["id"] = id
reviews_with_id.append(review)
return reviews_of_interest
The dictionaries returned contain a flattened version of the verbose output from the search_for_relevant_feedback task. They take the following format:
[
{
"ab_test_group": "A",
"customer_feedback": "The product did not meet my expectations, ugly UI.",
"customer_id": 1843,
"customer_location": "Switzerland",
"customer_rating": 1,
"product_type": "cloud service A",
"timestamp": "2023-11-24T11:25:37Z",
"id": "804dfcfd-62f5-5f8c-b64e-b167dcb4b1dc",
},
{
"ab_test_group": "A",
"customer_feedback": "This product has transformed the way I work, absolutely fantastic UX!",
"customer_id": 1714,
"customer_location": "Switzerland",
"customer_rating": 3,
"product_type": "cloud service A",
"timestamp": "2023-11-24T11:25:37Z",
"id": "9c3880f4-f883-50d2-8a41-056c0efe4b2b",
},
]
A second task, get_feedback_texts, is dynamically mapped over the list of dictionaries returned by the reformat_relevant_reviews task to extract the customer_feedback field from each dictionary.
@task
def get_feedback_texts(review_of_interest: dict) -> str:
"Get the feedback text from the relevant reviews."
feedback_text = review_of_interest["customer_feedback"]
return feedback_text
feedback_texts = get_feedback_texts.expand(review_of_interest=relevant_reviews)
Perform sentiment analysis on relevant customer feedback and get embeddings using the Cohere API
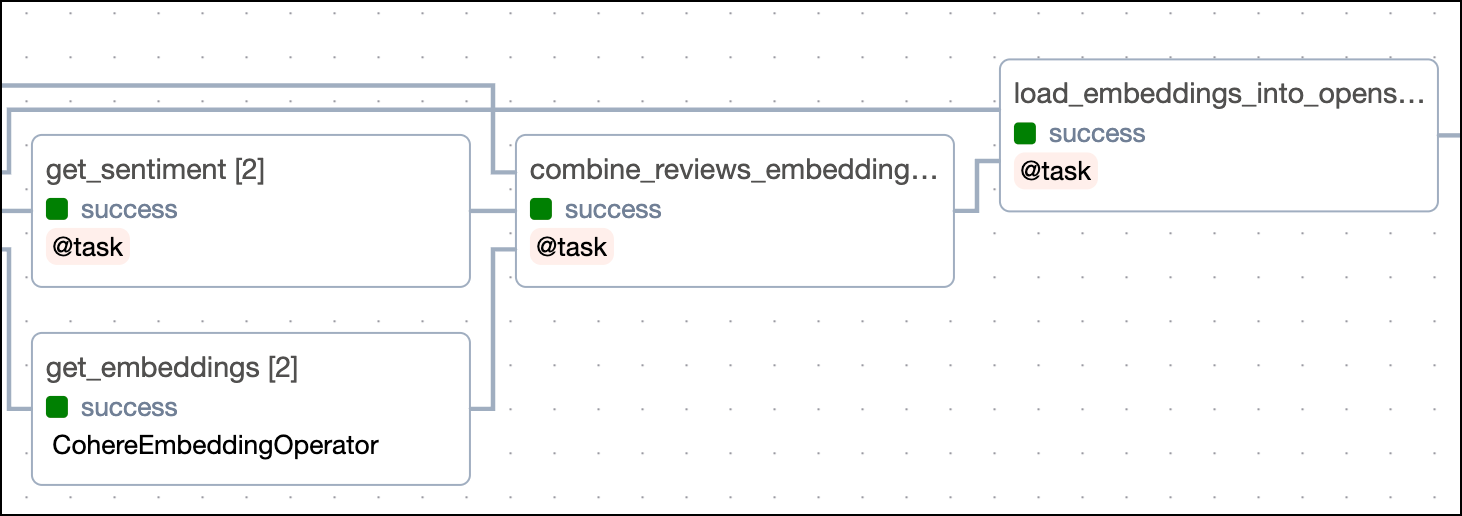
The third section of the DAG consists of four tasks that perform sentiment analysis, get vector embeddings and load the results back into OpenSearch.
The first task in this section, get_sentiment, uses the CohereHook to get the sentiment of the customer feedback using the Cohere API text classification endpoint. The task is dynamically mapped over the list of feedback texts returned by the get_feedback_texts task to create one mapped task instance per customer feedback to be analyzed in parallel. Sentiment examples are stored in the classification_examples file in the include folder.
@task
def get_sentiment(input_text: str, sentiment_examples: list, conn_id: str) -> float:
"Get the sentiment of the customer feedback using the Cohere API."
co = CohereHook(conn_id=conn_id).get_conn
response = co.classify(
model="large",
inputs=[input_text],
examples=sentiment_examples,
)
print(input_text)
print(response.classifications)
return {
"prediction": response.classifications[0].prediction,
"confidence": response.classifications[0].confidence,
}
sentiment_scores = get_sentiment.partial(
conn_id=COHERE_CONN_ID, sentiment_examples=SENTIMENT_EXAMPLES
).expand(input_text=feedback_texts)
Sentiment scores are returned in the format of:
{'prediction': 'positive', 'confidence': 0.9305259}
In parallel, the CohereEmbeddingOperator defines the get_embeddings task which uses the embedding endpoint of the Cohere API to get vector embeddings for customer feedback. Similar to the get_sentiment task, the get_embeddings task is dynamically mapped over the list of feedback texts returned by the get_feedback_texts task to create one mapped task instance per customer feedback to be embedded in parallel.
get_embeddings = CohereEmbeddingOperator.partial(
task_id="get_embeddings",
conn_id=COHERE_CONN_ID,
).expand(input_text=feedback_texts)
Next, the combine_reviews_embeddings_and_sentiments task combines the embeddings and sentiment scores into a single list of dictionaries.
@task
def combine_reviews_embeddings_and_sentiments(
reviews: list, embeddings: list, sentiments: list
) -> list:
"Combine the reviews, embeddings and sentiments into a single list of dictionaries."
review_with_embeddings = []
for review, embedding, sentiment in zip(reviews, embeddings, sentiments):
review_with_embeddings.append(
{
"review": review,
"embedding": embedding[0],
"sentiment_prediction": sentiment["prediction"],
"sentiment_confidence": sentiment["confidence"],
}
)
return review_with_embeddings
full_data = combine_reviews_embeddings_and_sentiments(
reviews=relevant_reviews,
embeddings=get_embeddings.output,
sentiments=sentiment_scores,
)
For each combined dictionary, the load_embeddings_into_opensearch task uses the OpenSearchHook to update the relevant document in OpenSearch with the embeddings and sentiment scores.
@task
def load_embeddings_into_opensearch(full_data: dict, conn_id: str) -> None:
"Load the embeddings and sentiment into OpenSearch."
client = OpenSearchHook(open_search_conn_id=conn_id, log_query=True).client
client.update(
index=OPENSEARCH_INDEX_NAME,
id=full_data["review"]["id"],
body={
"doc": {
"embeddings": [float(x) for x in full_data["embedding"]],
"sentiment_prediction": full_data["sentiment_prediction"],
"sentiment_confidence": full_data["sentiment_confidence"],
}
},
)
load_embeddings_obj = load_embeddings_into_opensearch.partial(
conn_id=OPENSEARCH_CONN_ID
).expand(full_data=full_data)
Query OpenSearch for the most similar testimonial using k-NN on the embeddings and filter for positive sentiment
The final section of the DAG queries OpenSearch using both k-NN on the embeddings and a filter on the sentiment scores to get the most similar positive customer feedback to a target testimonial.
First, the get_embeddings_testimonial_search_term task converts the target testimonial to vector embeddings using the CohereEmbeddingOperator.
get_embeddings_testimonial_search_term = CohereEmbeddingOperator(
task_id="get_embeddings_testimonial_search_term",
conn_id=COHERE_CONN_ID,
input_text=TESTIMONIAL_SEARCH_TERM,
)
Next, the prep_search_term_embeddings_for_query task converts the embeddings returned by the get_embeddings_testimonial_search_term task to a list of floats to be used in the OpenSearch query.
@task
def prep_search_term_embeddings_for_query(embeddings: list) -> list:
"Prepare the embeddings for the OpenSearch query."
return [float(x) for x in embeddings[0]]
search_term_embeddings = prep_search_term_embeddings_for_query(
embeddings=get_embeddings_testimonial_search_term.output
)
The search_for_testimonial_candidates task uses the OpenSearchQueryOperator to query OpenSearch for the most similar customer feedback to the target testimonial using a k-NN algorithm on the embeddings and filter for positive sentiment. Note that k-NN search requires the knn plugin to be installed in OpenSearch.
search_for_testimonial_candidates = OpenSearchQueryOperator(
task_id="search_for_testimonial_candidates",
opensearch_conn_id=OPENSEARCH_CONN_ID,
index_name=OPENSEARCH_INDEX_NAME,
query={
"size": 10,
"query": {
"bool": {
"must": [
{
"knn": {
"embeddings": {
"vector": search_term_embeddings,
"k": 10,
}
}
}
],
"filter": [
{"term": {"sentiment_prediction": "positive"}},
],
}
},
},
)
Lastly, the print_testimonial_candidates task prints positive customer feedback that is closest to the target testimonial feedback and mentions the user experience of the cloud A service to the logs.
@task
def print_testimonial_candidates(search_results: dict) -> None:
"Print the testimonial candidates from the OpenSearch query results."
for result in search_results["hits"]["hits"]:
print("Customer ID: ", result["_source"]["customer_id"])
print("Customer feedback: ", result["_source"]["customer_feedback"])
print("Customer location: ", result["_source"]["customer_location"])
print("Customer rating: ", result["_source"]["customer_rating"])
print("Customer sentiment: ", result["_source"]["sentiment_prediction"])
print(
"Customer sentiment confidence: ",
result["_source"]["sentiment_confidence"],
)
You can review the output of the task in the task logs. They should look similar to the following:
[2023-11-24, 11:25:48 UTC] {logging_mixin.py:154} INFO - Customer ID: 1714
[2023-11-24, 11:25:48 UTC] {logging_mixin.py:154} INFO - Customer feedback: This product has transformed the way I work, absolutely fantastic UX!
[2023-11-24, 11:25:48 UTC] {logging_mixin.py:154} INFO - Customer location: Switzerland
[2023-11-24, 11:25:48 UTC] {logging_mixin.py:154} INFO - Customer rating: 3
[2023-11-24, 11:25:48 UTC] {logging_mixin.py:154} INFO - Customer sentiment: positive
[2023-11-24, 11:25:48 UTC] {logging_mixin.py:154} INFO - Customer sentiment confidence: 0.99412733
Congratulations! You've successfully run a full MLOps pipeline with Airflow, Cohere, and OpenSearch which efficiently finds a customer feedback testimonial based on a set of parameters, including its sentiment and similarity to a target testimonial.
See also
- Tutorial: Orchestrate OpenSearch operations with Apache Airflow.
- Tutorial: Orchestrate Cohere LLMs with Apache Airflow
- Documentation: Airflow OpenSearch provider documentation.
- Documentation: Airflow Cohere provider documentation.