Processing User Feedback: an LLM-fine-tuning reference architecture with Ray on Anyscale
The Processing User Feedback GitHub repository is a free and open-source reference architecture showing how to use Apache Airflow® with Anyscale, a distributed compute platform built on Ray, to build an automated system that processes and categorizes user feedback relating to video games using a fine-tuned Large Language Model (LLM). The repository includes full source code, documentation, and deployment instructions for you to adapt and implement this architecture in your own projects.
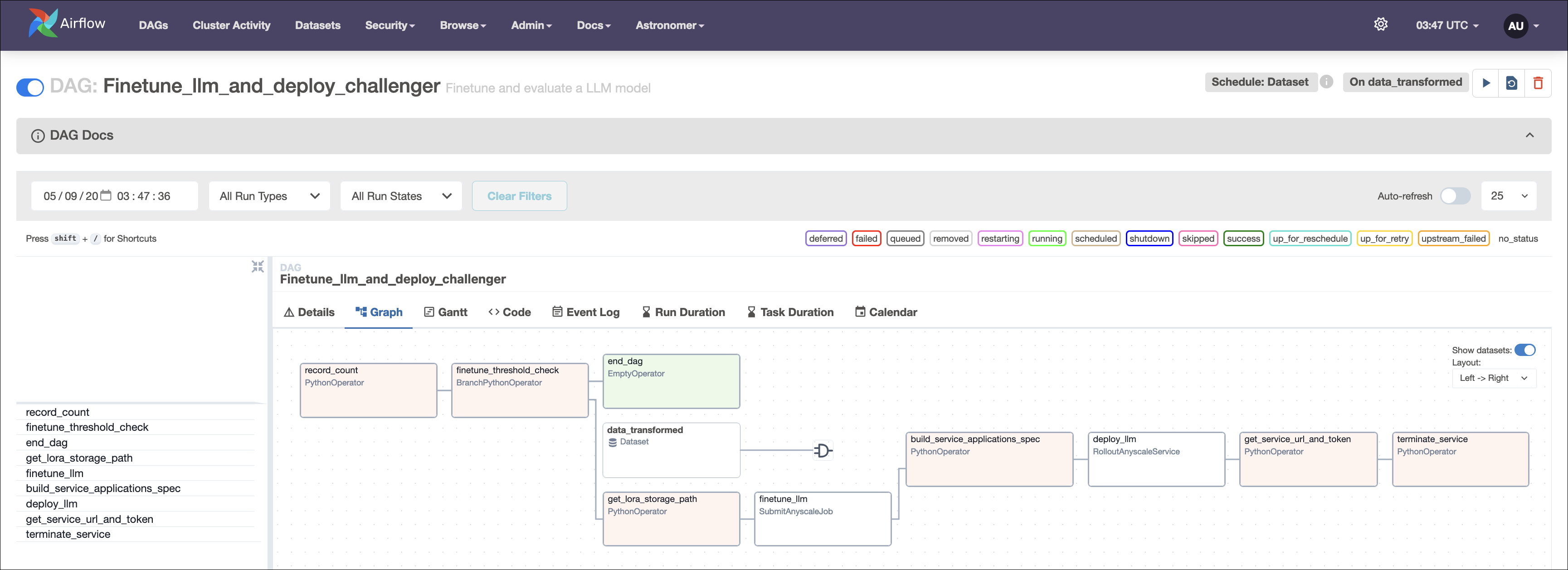
This reference architecture serves as a practical learning tool, illustrating how to use Apache Airflow to orchestrate fine-tuning of LLMs on the Anyscale platform. The Processing User Feedback application is designed to be adaptable, allowing you to tailor it to your specific use case. You can customize the workflow by:
- Changing the data that is ingested for fine-tuning and inference.
- Modifying the Anyscale jobs and services to align with your requirements.
- Adjusting the data processing steps and model fine-tuning parameters.
By providing a flexible framework, this architecture enables developers and data scientists to implement and scale their own LLM-based feedback processing systems using distributed compute.
This tutorial uses Anyscale with the Anyscale provider to run Ray jobs. If you want to run Ray jobs on other platforms, you can use the Ray provider instead. See also Orchestrate Ray jobs on Anyscale with Apache Airflow®.
Architecture
The Processing User Feedback use case consists of 2 main components:
- Data ingestion: new user feedback about video games is collected from several APIs, preprocessed, and stored in an S3 bucket.
- Fine-tuning and deploying of Mistral-7B: once a threshold of 200 new feedback entries is reached, the data is used to fine-tune a pre-trained LLM model, Mistral-7B, on Anyscale using distributed compute. The fine-tuned model is deployed using Anyscale Services.
Additionally, the architecture includes an advanced champion-challenger version of the fine-tuning process.
Airflow features
The DAGs in this reference architecture highlight several key Airflow features and best practices:
- Branching: Using Airflow Branching, DAGs can execute different paths based on runtime conditions or results from previous tasks. This allows for dynamic workflow adjustments depending on the data or processing requirements. In this reference architecture branching is used to determine whether the fine-tuning process should be executed.
- Airflow retries: To protect against transient API failures and rate limits, all tasks are configured to automatically retry after an adjustable delay.
- Dynamic task mapping: Transforming data from multiple data sources is split into multiple parallelized tasks using dynamic task mapping. The number of parallelized tasks is determined at runtime based on the number of data sources that need to be processed.
- Data-aware scheduling: The DAGs run on a data-driven schedule to regularly and automatically update the LLM model when new data has been ingested. Aside from data-driven scheduling, Airflow offers options such as time-based scheduling or scheduling based on external events detected using sensors.
- Task groups: In the champion-challenger DAG, related tasks are organized into logical groups within the DAG with Airflow task groups. This improves the overall structure of complex workflows and makes them easier to understand and maintain.
Next Steps
Get the Astronomer GenAI cookbook to view more examples of how to use Airflow to build generative AI applications.
If you'd like to build your own pipeline using Anyscale with Airflow, feel free to fork the repository and adapt it to your use case. We recommend deploying the Airflow pipelines using a free trial of Astro.