Introduction to Airflow DAGs
In Airflow, a DAG is a data pipeline or workflow. DAGs are the main organizational unit in Airflow; they contain a collection of tasks and dependencies that you want to execute on a schedule.
A DAG is defined in Python code and visualized in the Airflow UI. DAGs can be as simple as a single task or as complex as hundreds or thousands of tasks with complicated dependencies.
The following screenshot shows a complex DAG graph in the Airflow UI. After reading this guide, you'll be able to understand the elements in this graph, as well as know how to define DAGs and use DAG parameters.
There are multiple resources for learning about this topic. See also:
- Astronomer Academy: Airflow: DAGs 101 module.
Assumed knowledge
To get the most out of this guide, you should have an understanding of:
- What Airflow is. See Introduction to Apache Airflow.
What is a DAG?
A DAG (directed acyclic graph) is a mathematical structure consisting of nodes and edges. In Airflow, a DAG represents a data pipeline or workflow with a start and an end.
The mathematical properties of DAGs make them useful for building data pipelines:
-
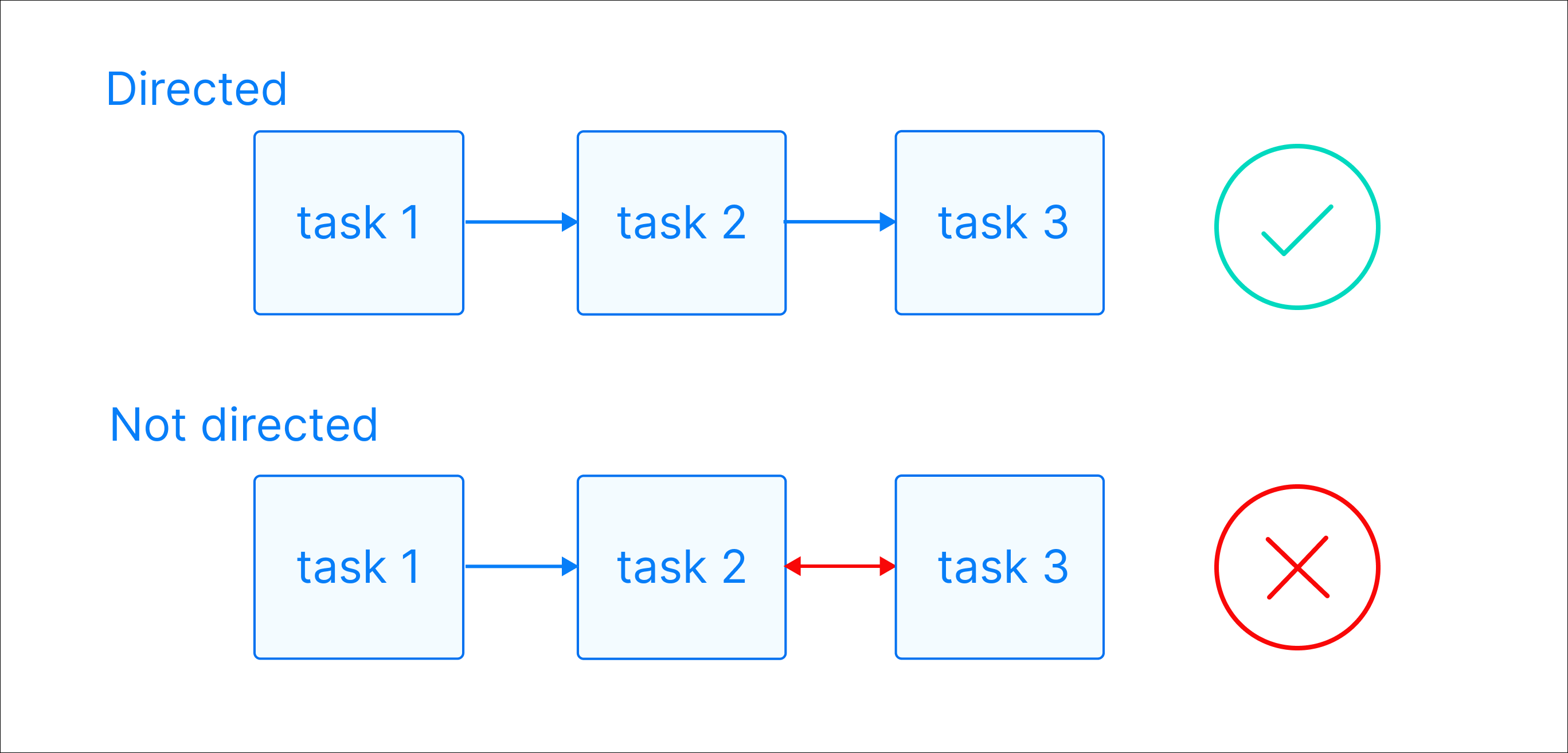
Directed: There is a clear direction of flow between tasks. A task can be either upstream, downstream, or parallel to another task.
-
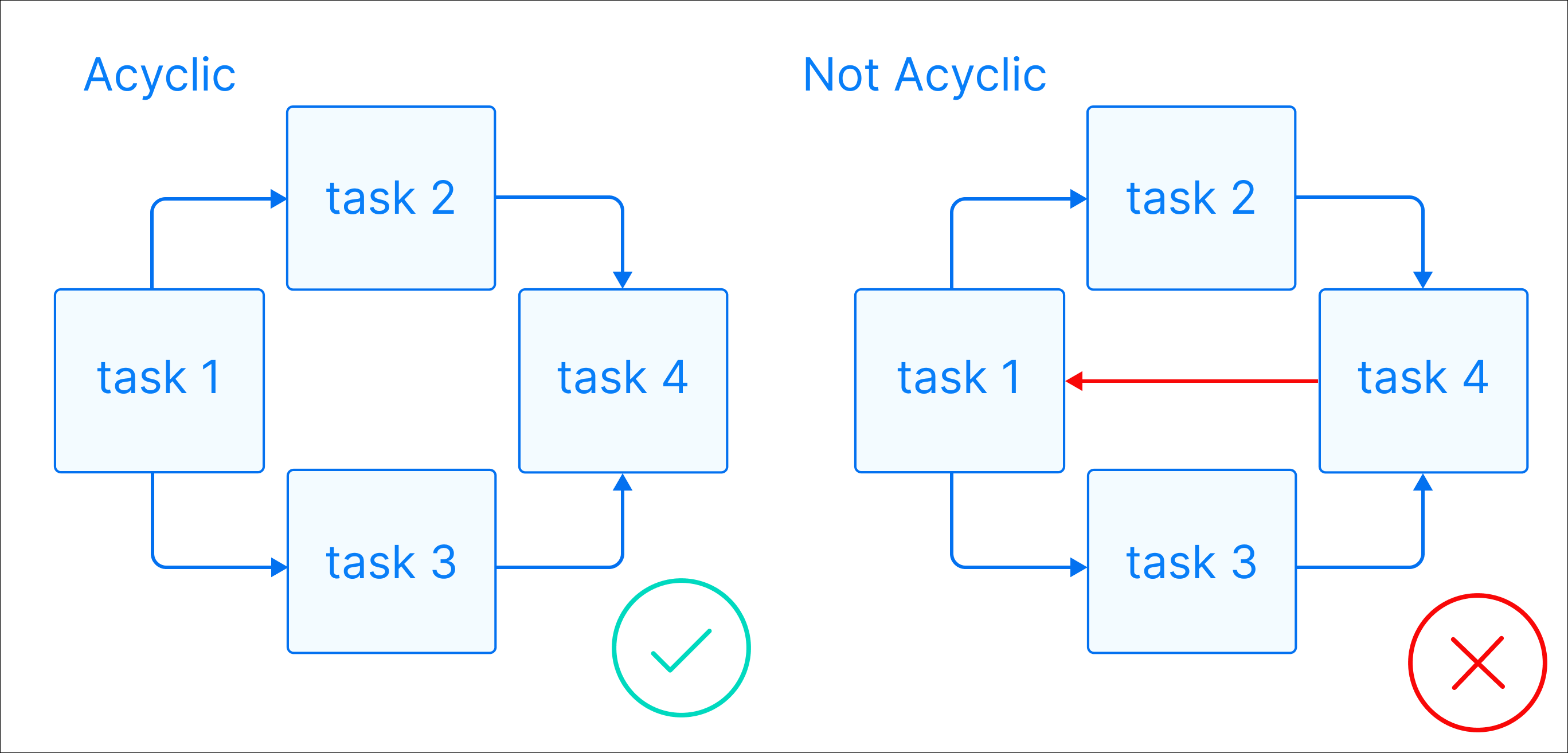
Acyclic: There are no circular dependencies in a DAG. This means that a task cannot depend on itself, nor can it depend on a task that ultimately depends on it.
-
Graph: A DAG is a graph, which is a structure consisting of nodes and edges. In Airflow, nodes are tasks and edges are dependencies between tasks. Defining workflows as graphs helps you visualize the entire workflow in a way that's easy to navigate and conceptualize.
Beyond these requirements, a DAG can be as simple or as complicated as you need! You can define tasks that run in parallel or sequentially, implement conditional branches, and visually group tasks together in task groups.
Each task in a DAG performs one unit of work. Tasks can be anything from a simple Python function to a complex data transformation or a call to an external service. They are defined using Airflow operators or Airflow decorators. The dependencies between tasks can be set in different ways (see Managing Dependencies).
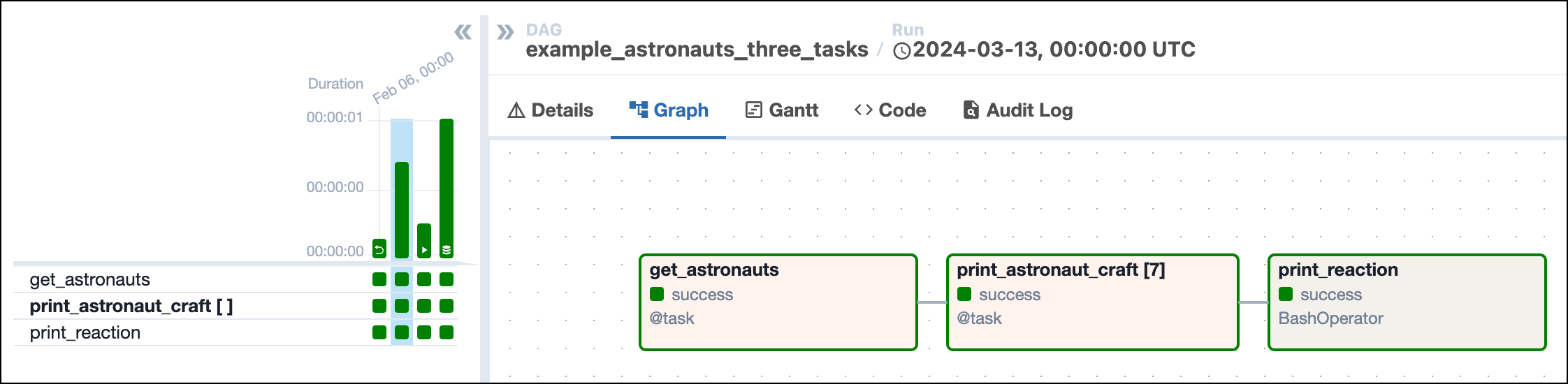
The following screenshot shows a simple DAG graph with 3 sequential tasks.

Click to view the full DAG code used to create the DAG in the screenshot
"""
## Astronaut ETL example DAG
This DAG queries the list of astronauts currently in space from the
Open Notify API and prints each astronaut's name and flying craft.
There are three tasks, one to get the data from the API and save the results,
one to print the results and a final task to react. The first two tasks are
written in Python using Airflow's TaskFlow API, which allows you to easily turn
Python functions into Airflow tasks, and automatically infer dependencies and pass data.
The second task uses dynamic task mapping to create a copy of the task for
each Astronaut in the list retrieved from the API. This list will change
depending on how many Astronauts are in space, and the DAG will adjust
accordingly each time it runs.
The third task is defined using the BashOperator, which is a traditional
operator, allowing you to run a bash command.
"""
from airflow.decorators import dag, task
from airflow.operators.bash import BashOperator
from airflow.models.baseoperator import chain
from pendulum import datetime
import requests
# Define the basic parameters of the DAG, like schedule and start_date
@dag(
start_date=datetime(2024, 1, 1),
schedule="@daily",
catchup=False,
doc_md=__doc__,
default_args={"owner": "Astro", "retries": 3},
tags=["example"],
)
def example_astronauts_three_tasks():
# Define tasks
@task
def get_astronauts(**context) -> list[dict]:
"""
This task uses the requests library to retrieve a list of Astronauts
currently in space. The results are pushed to XCom with a specific key
so they can be used in a downstream pipeline. The task returns a list
of Astronauts to be used in the next task.
"""
r = requests.get("http://api.open-notify.org/astros.json")
number_of_people_in_space = r.json()["number"]
list_of_people_in_space = r.json()["people"]
context["ti"].xcom_push(
key="number_of_people_in_space", value=number_of_people_in_space
)
return list_of_people_in_space
@task
def print_astronaut_craft(greeting: str, person_in_space: dict) -> None:
"""
This task creates a print statement with the name of an
Astronaut in space and the craft they are flying on from
the API request results of the previous task, along with a
greeting which is hard-coded in this example.
"""
craft = person_in_space["craft"]
name = person_in_space["name"]
print(f"{name} is currently in space flying on the {craft}! {greeting}")
# define a task using a traditional operator
# this task will run a bash command
print_reaction = BashOperator(
task_id="print_reaction",
bash_command="echo This is awesome!",
)
# Use dynamic task mapping to run the print_astronaut_craft task for each
# Astronaut in space
print_astronaut_craft_obj = print_astronaut_craft.partial(
greeting="Hello! :)"
).expand(
person_in_space=get_astronauts() # Define dependencies using TaskFlow API syntax
)
# set the dependency between the second and third task explicitly
chain(print_astronaut_craft_obj, print_reaction)
# Instantiate the DAG
example_astronauts_three_tasks()
What is a DAG run?
A DAG run is an instance of a DAG running at a specific point in time. A task instance, also known as a task run, is an instance of a task running at a specific point in time. Each DAG run has a unique dag_run_id and contains one or more task instances. The history of previous DAG runs is stored in the Airflow metadata database.
In the Airflow UI, you can view previous runs of a DAG in the Grid view and select individual DAG runs by clicking on their respective duration bar. A DAG run graph looks similar to the DAG graph, but includes additional information about the status of each task instance in the DAG run.
DAG run properties
A DAG run graph in the Airflow UI contains information about the DAG run, as well as the status of each task instance in the DAG run. The following screenshot shows the same DAG as in the previous section, but with annotations explaining the different elements of the graph.
![Screenshot of the Airflow UI showing the Grid view with the Graph tab selected. A DAG run with 3 tasks is shown. The annotations show the location of the dag_id and logical date (top of the screenshot), the task_id, task state and operator/decorator used in the nodes of the graph, as well as the number of dynamically mapped task instances in [] behind the task id and the DAG dependency layout to the right of the screen.](/docs/assets/images/dags_simple_dag_run_graph_annotated-970ede1933fb2bbd5bb2e76225e7e4bd.png)
dag_id: The unique identifier of the DAG.logical date: The point in time for which the DAG run is scheduled. This date and time is not necessarily the same as the actual moment the DAG run is executed. See Scheduling for more information.task_id: The unique identifier of the task.task state: The status of the task instance in the DAG run. Possible states arerunning,success,failed,skipped,restarting,up_for_retry,upstream_failed,queued,scheduled,none,removed,deferred, andup_for_reschedule, they each cause the border of the node to be colored differently. See the OSS documentation on task instances for an explanation of each state.
The previous screenshot also shows the four common ways you can trigger a DAG run:
- Backfill: The first DAG run was created using a backfill. Backfilled DAG runs include a curved arrow on their DAG run duration bar.
- Scheduled: The second DAG run, which is currently selected in the screenshot, was created by the Airflow scheduler based on the DAG's defined schedule. This is the default method for running DAGs.
- Manual: The third DAG run was triggered manually by a user using the Airflow UI or the Airflow CLI. Manually triggered DAG runs include a play icon on the DAG run duration bar.
- Dataset triggered: The fourth DAG run was started by a dataset. DAG runs triggered by a dataset include a dataset icon on their DAG run duration bar.
A DAG run can have the following statuses:
- Queued: The time after which the DAG run can be created has passed but the scheduler has not created task instances for it yet.
- Running: The DAG run is eligible to have task instances scheduled.
- Success: All task instances are in a terminal state (
success,skipped,failedorupstream_failed) and all leaf tasks (tasks with no downstream tasks) are either in the statesuccessorskipped. In the previous screenshot, all four DAG runs were successful. - Failed: All task instances are in a terminal state and at least one leaf task is in the state
failedorupstream_failed.
Complex DAG runs
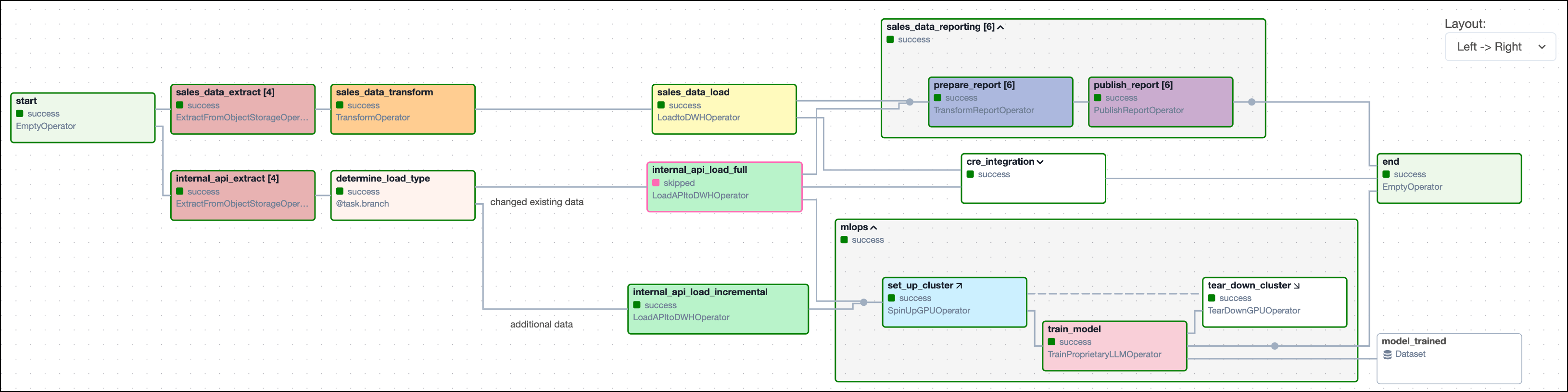
When you start writing more complex DAGs, you will see additional Airflow features that are visualized in the DAG run graph. The following screenshot shows the same complex DAG as in the overview but with annotations explaining the different elements of the graph. Don't worry if you don't know about all these features yet - you will learn about them as you become more familiar with Airflow.
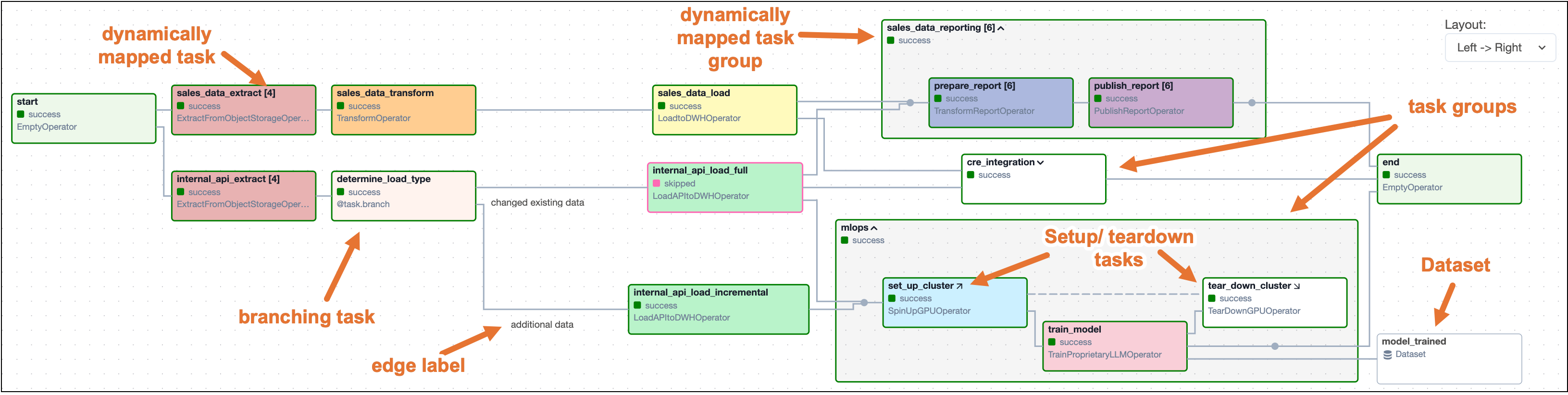
Click to view the full DAG code used for the screenshot
The following code creates the same DAG structure as shown in the previous screenshot. Note that custom operators have been replaced with the BashOperator and EmptyOperator to make it possible to run the DAG without additional setup.
"""
## Example of a complex DAG structure
This DAG demonstrates how to set up a complex structures including:
- Branches with Labels
- Task Groups
- Dynamically mapped tasks
- Dynamically mapped task groups
The tasks themselves are empty or simple bash statements.
"""
from airflow.decorators import dag, task_group, task
from airflow.operators.empty import EmptyOperator
from airflow.operators.bash import BashOperator
from airflow.models.baseoperator import chain, chain_linear
from airflow.utils.edgemodifier import Label
from airflow.datasets import Dataset
from pendulum import datetime
# Define the DAG
@dag(
start_date=datetime(2024, 1, 1),
schedule=None,
catchup=False,
)
def complex_dag_structure():
start = EmptyOperator(task_id="start")
# Dynamically mapped tasks: .partial() contains all parameters that stay the same
# between mapped task instances. .expand() contains the parameters that change
# one mapped task instance will be created for each value in the list provided to `bash_command`
sales_data_extract = BashOperator.partial(task_id="sales_data_extract").expand(
bash_command=["echo 1", "echo 2", "echo 3", "echo 4"]
)
internal_api_extract = BashOperator.partial(task_id="internal_api_extract").expand(
bash_command=["echo 1", "echo 2", "echo 3", "echo 4"]
)
# Branch task that picks which branch to follow
@task.branch
def determine_load_type() -> str:
"""Randomly choose a branch. The return value is the task_id of the branch to follow."""
import random
if random.choice([True, False]):
return "internal_api_load_full"
return "internal_api_load_incremental"
sales_data_transform = EmptyOperator(task_id="sales_data_transform")
# When using the TaskFlow API it is common to assing the called task to an object
# to use in several dependency definitions without creating several instances of the same task
determine_load_type_obj = determine_load_type()
sales_data_load = EmptyOperator(task_id="sales_data_load")
internal_api_load_full = EmptyOperator(task_id="internal_api_load_full")
internal_api_load_incremental = EmptyOperator(
task_id="internal_api_load_incremental"
)
# defining a task group that task a parameter (a) to allow for dynamic task group mapping
@task_group
def sales_data_reporting(a):
# the trigger_rule of the first task in the task group can be set to "all_done"
# to ensure that it runs even if one of the upstream tasks (`internal_api_load_full`)
# is skipped due to the branch task
prepare_report = EmptyOperator(
task_id="prepare_report", trigger_rule="all_done"
)
publish_report = EmptyOperator(task_id="publish_report")
# setting dependencies within the task group
chain(prepare_report, publish_report)
# dynamically mapping the task group with `a` being the mapped parameter
# one task group instance will be created for each value in the list provided to `a`
sales_data_reporting_obj = sales_data_reporting.expand(a=[1, 2, 3, 4, 5, 6])
# defining a task group that does not use any additional parameters
@task_group
def cre_integration():
# the trigger_rule of the first task in the task group can be set to "all_done"
# to ensure that it runs even if one of the upstream tasks (`internal_api_load_full`)
# is skipped due to the branch task
cre_extract = EmptyOperator(task_id="cre_extract", trigger_rule="all_done")
cre_transform = EmptyOperator(task_id="cre_transform")
cre_load = EmptyOperator(task_id="cre_load")
# setting dependencies within the task group
chain(cre_extract, cre_transform, cre_load)
# calling the task group to instantiate it and assigning it to an object
# to use in dependency definitions
cre_integration_obj = cre_integration()
@task_group
def mlops():
# the trigger_rule of the first task in the task group can be set to "all_done"
# to ensure that it runs even if one of the upstream tasks (`internal_api_load_incremental`)
# is skipped due to the branch task
set_up_cluster = EmptyOperator(
task_id="set_up_cluster", trigger_rule="all_done"
)
# the outlets parameter is used to define which datasets are updated by this task
train_model = EmptyOperator(
task_id="train_model", outlets=[Dataset("model_trained")]
)
tear_down_cluster = EmptyOperator(task_id="tear_down_cluster")
# setting dependencies within the task group
chain(set_up_cluster, train_model, tear_down_cluster)
# turning the `tear_down_cluster`` task into a teardown task and set
# the `set_up_cluster` task as the associated setup task
tear_down_cluster.as_teardown(setups=set_up_cluster)
mlops_obj = mlops()
end = EmptyOperator(task_id="end")
# --------------------- #
# Defining dependencies #
# --------------------- #
chain(
start,
sales_data_extract,
sales_data_transform,
sales_data_load,
[sales_data_reporting_obj, cre_integration_obj],
end,
)
chain(
start,
internal_api_extract,
determine_load_type_obj,
[internal_api_load_full, internal_api_load_incremental],
mlops_obj,
end,
)
chain_linear(
[sales_data_load, internal_api_load_full],
[sales_data_reporting_obj, cre_integration_obj],
)
# Adding labels to two edges
chain(
determine_load_type_obj, Label("additional data"), internal_api_load_incremental
)
chain(
determine_load_type_obj, Label("changed existing data"), internal_api_load_full
)
# Calling the DAG function will instantiate the DAG
complex_dag_structure()
Some more complex features visible in this DAG graph are:
- Dynamically mapped tasks: A dynamically mapped task is created dynamically at runtime based on user-defined input. The number of dynamically mapped task instances is shown in brackets (
[]) behind the task ID. - Branching tasks: A branching task creates a conditional branch in the DAG. See Branching in Airflow for more information.
- Edge labels: Edge labels appear on the edge between two tasks. These labels are often helpful to annotate branch decisions in a DAG graph.
- Task groups: A task group is a tool to logically and visually group tasks in an Airflow DAG. See Airflow task groups for more information.
- Setup/teardown tasks: When using Airflow to manage infrastructure, it can be helpful to define tasks as setup and teardown tasks to take advantage of additional intelligent dependency behavior. Setup and teardown tasks appear with diagonal arrows next to their task IDs and are connected with a dotted line. See Use setup and teardown tasks in Airflow for more information.
- Datasets: Datasets are shown in the DAG graph. If a DAG is scheduled on a dataset, it is shown upstream of the first task of the DAG. If a task in the DAG updates a dataset, it is shown after the respective task as in the previous screenshot. See Airflow datasets for more information.
You can learn more about how to set complex dependencies between tasks and task groups in the Managing Dependencies guide.
Write a DAG
A DAG can be defined with a Python file placed in an Airflow project's DAG_FOLDER, which is dags when using the Astro CLI. Airflow automatically parses all files in this folder every 5 minutes to check for new DAGs, and it parses existing DAGs for code changes every 30 seconds. You can force a new DAG parse using airflow dags reserialize, or astro dev run dags reserialize using the Astro CLI.
There are two types of syntax you can use to structure your DAG:
- TaskFlow API: The TaskFlow API contains the
@dagdecorator. A function decorated with@dagdefines a DAG. Note that you need to call the function at the end of the script for Airflow to register the DAG. All tasks are defined within the context of the DAG function. - Traditional syntax: You can create a DAG by instantiating a DAG context using the
DAGclass and defining tasks within that context.
TaskFlow API and traditional syntax can be freely mixed. See Mixing TaskFlow decorators with traditional operators for more information.
The following is an example of the same DAG written using each type of syntax.
- TaskFlow API
- Traditional syntax
# Import all packages needed at the top level of the DAG
from airflow.decorators import dag, task
from airflow.models.baseoperator import chain
from pendulum import datetime
# Define the DAG function a set of parameters
@dag(
start_date=datetime(2024, 1, 1),
schedule="@daily",
catchup=False,
)
def taskflow_dag():
# Define tasks within the DAG context
@task
def my_task_1():
import time # import packages only needed in the task function
time.sleep(5)
print(1)
@task
def my_task_2():
print(2)
# Define dependencies and call task functions
chain(my_task_1(), my_task_2())
# Call the DAG function
taskflow_dag()
# Import all packages needed at the top level of the DAG
from airflow import DAG
from airflow.operators.python import PythonOperator
from pendulum import datetime
def my_task_1_func():
import time # import packages only needed in the task function
time.sleep(5)
print(1)
# Instantiate the DAG
with DAG(
dag_id="traditional_syntax_dag",
start_date=datetime(2024, 1, 1),
schedule="@daily",
catchup=False,
):
# Instantiate tasks within the DAG context
my_task_1 = PythonOperator(
task_id="my_task_1",
python_callable=my_task_1_func,
)
my_task_2 = PythonOperator(
task_id="my_task_2",
python_callable=lambda: print(2),
)
# Define dependencies
my_task_1 >> my_task_2
Astronomer recommends creating one Python file for each DAG and naming it after the dag_id as a best practice for organizing your Airflow project. For certain advanced use cases it may be appropriate to dynamically generate DAGs using Python code, see Dynamically generate DAGs in Airflow for more information.
DAG-level parameters
In Airflow, you can configure when and how your DAG runs by setting parameters in the DAG object. DAG-level parameters affect how the entire DAG behaves, as opposed to task-level parameters which only affect a single task.
The DAGs in the previous section have the following basic parameters defined. It's best practice to always define these parameters for any DAGs you create:
dag_id: The name of the DAG. This must be unique for each DAG in the Airflow environment. When using the@dagdecorator and not providing thedag_idparameter name, the function name is used as thedag_id.start_date: The date and time after which the DAG starts being scheduled.schedule: The schedule for the DAG. There are many different ways to define a schedule, see Scheduling in Airflow for more information.catchup: Whether the scheduler should backfill all missed DAG runs between the current date and the start date when the DAG is unpaused. It is a best practice to always set it toFalseunless you specifically want to backfill missed DAG runs.
There are many more DAG-level parameters that let you configure anything from resource usage to the DAG's appearance in the Airflow UI. See DAG-level parameters for a complete list.
See also
- Get started with Apache Airflow tutorial for a hands-on introduction to writing your first simple DAG.
- Airflow operators and Introduction to the TaskFlow API and Airflow decorators for more information on how to define tasks in a DAG.
- Intro to Airflow: Get Started Writing Pipelines for Any Use Case webinar for a one-hour webinar introducing Airflow and how to write DAGs.