Leveraging data products for health and performance benefits
A data product is a pipeline-driven asset that captures the data lifecycle of a pipeline. Tasks, datasets, warehouse tables, and local files can all be assets of data products. Data products are abstractions that serve the purpose of gaining observability into the health and performance of data pipelines.
See also:
When to define a data product
Not all tasks and datasets are critical to business needs or internal teams, so it pays to be deliberate when creating data products.
Consider creating a data product when the end result of one or more pipelines:
- Is crucial for business operations, decision-making, or compliance.
- Is depended on by multiple teams or external partners.
- Involves complex processes or multiple sources.
- Is subject to regulatory requirements (GDPR, HIPAA).
- Contains or touches sensitive data such as customer data or PII.
- Is required to be available at a particular time.
Examples
Defining a data product makes particular sense when business-critical data are involved, multiple teams touch the pipeline, and on-time delivery and reliability of the data are of primary importance.
For example, say your organization manages warehouse tables containing data produced by multiple teams, and the data in the tables feed an analytics dashboard used by your executive team.
Creating a data product for these critical assets would enable visualization and monitoring of the flow of data through the distributed tasks that generate and modify the tables.
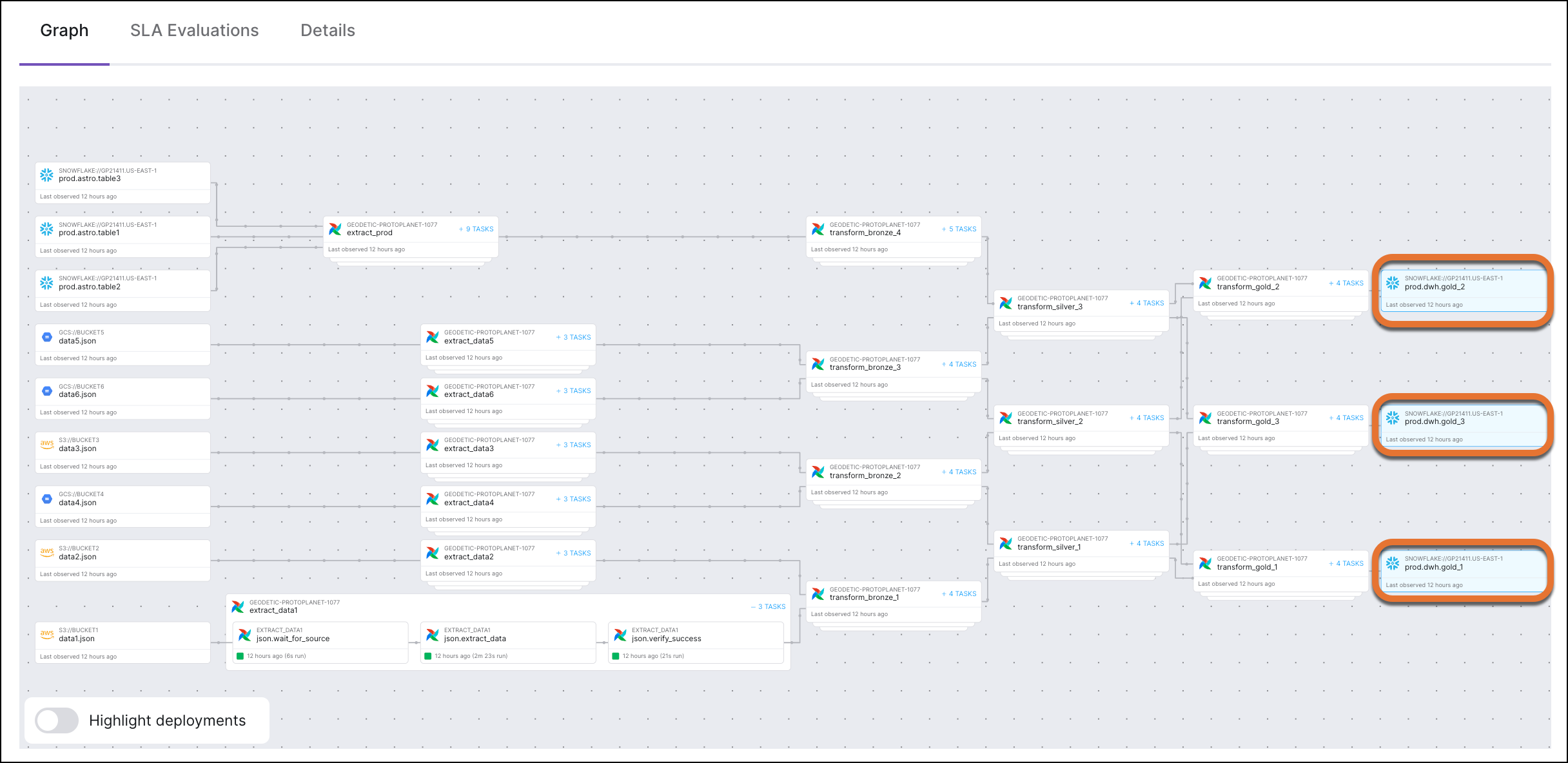
In Astro Observe (public preview), you would see a lineage graph that visualized the path of the dashboard's data from all their sources through the DAGs that extracted, transformed, and loaded the data into the data product.
Each node would represent an asset with a unique identifier, the emitting system (Apache Airflow, Snowflake), and the length of time since the asset was last observed.
Expanding a nested DAG node would reveal connected task nodes, each with a unique identifier, the containing DAG, the task status, the run duration, and the time since the task was last observed.
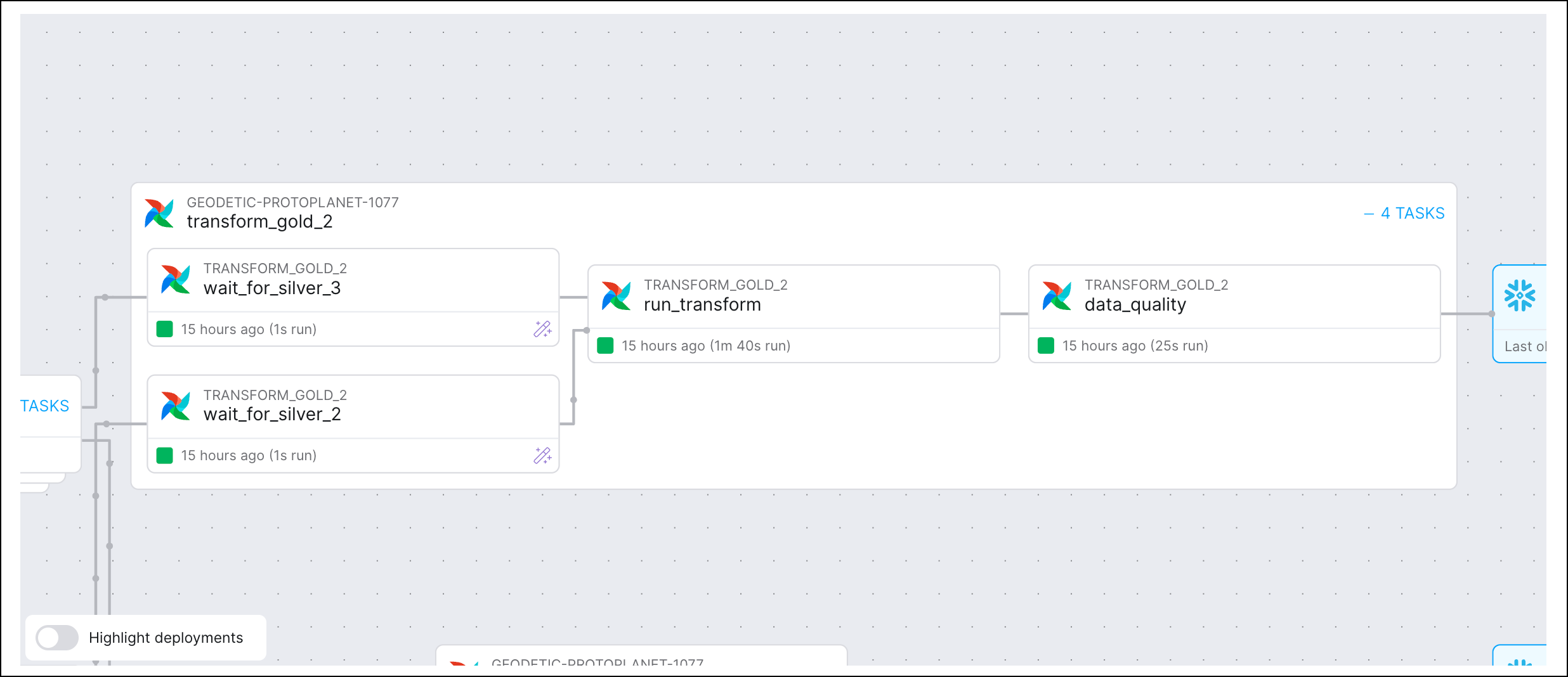
A key benefit of a lineage graph is how easy it makes identifying upstream assets, offering visibility into the tasks that could delay delivery or compromise the quality of business-critical data if they failed, along with the owners of those tasks.
Metadata collection enabled by data products also unlocks analytics, monitoring, and alerting, including proactive alerting using SLAs. For example, on Astro Observe, you could use the SLA hit rate metric to identify performance issues before they broke a dashboard like this.
Other assets for which you might want to define data products include:
- A file used by multiple teams to generate business-critical reports.
- A table containing customer data accessed by multiple teams in your organization.
Examples of when it probably does not make sense to define data products:
- A single upstream task hits an API endpoint.
- A transformation task in an ETL pipeline is upstream of a dependent load task already included in a data product.
- A table with non-critical or non-sensitive data in a sandbox is used only occasionally.
Considerations when using data products
Data products unlock insights available from data lineage. In general, data lineage enables:
- Visualization of upstream and downstream depdencies of tasks and datasets including at the column level when supported by tooling.
- Impact analysis including scoring.
- Data quality information including alerting and scoring.
- SLA evaluation and alerting when SLAs miss.
- Tagging of assets, for example when a table contains PII.
- Dataset metadata such as the datasource, format, schema (including changes), and data types.
- Task metadata such as the owners (including ownership changes), lifecycle state and state changes, source code or query, and job type.
Leveraging data products on Astro
On Astro, a data product is a special status you can apply to tasks and data assets such as warehouse tables and data lake buckets in your DAGs. When you create a data product in Astro Observe (public preview) based on a data asset such as a data lake bucket, warehouse table, or Airflow task, you enable observability into:
-
Upstream and downstream dependencies. A responsive graph displays the relationships between the data product and the other assets and tasks that either feed into it or are fed by it in the context of the DAG.
-
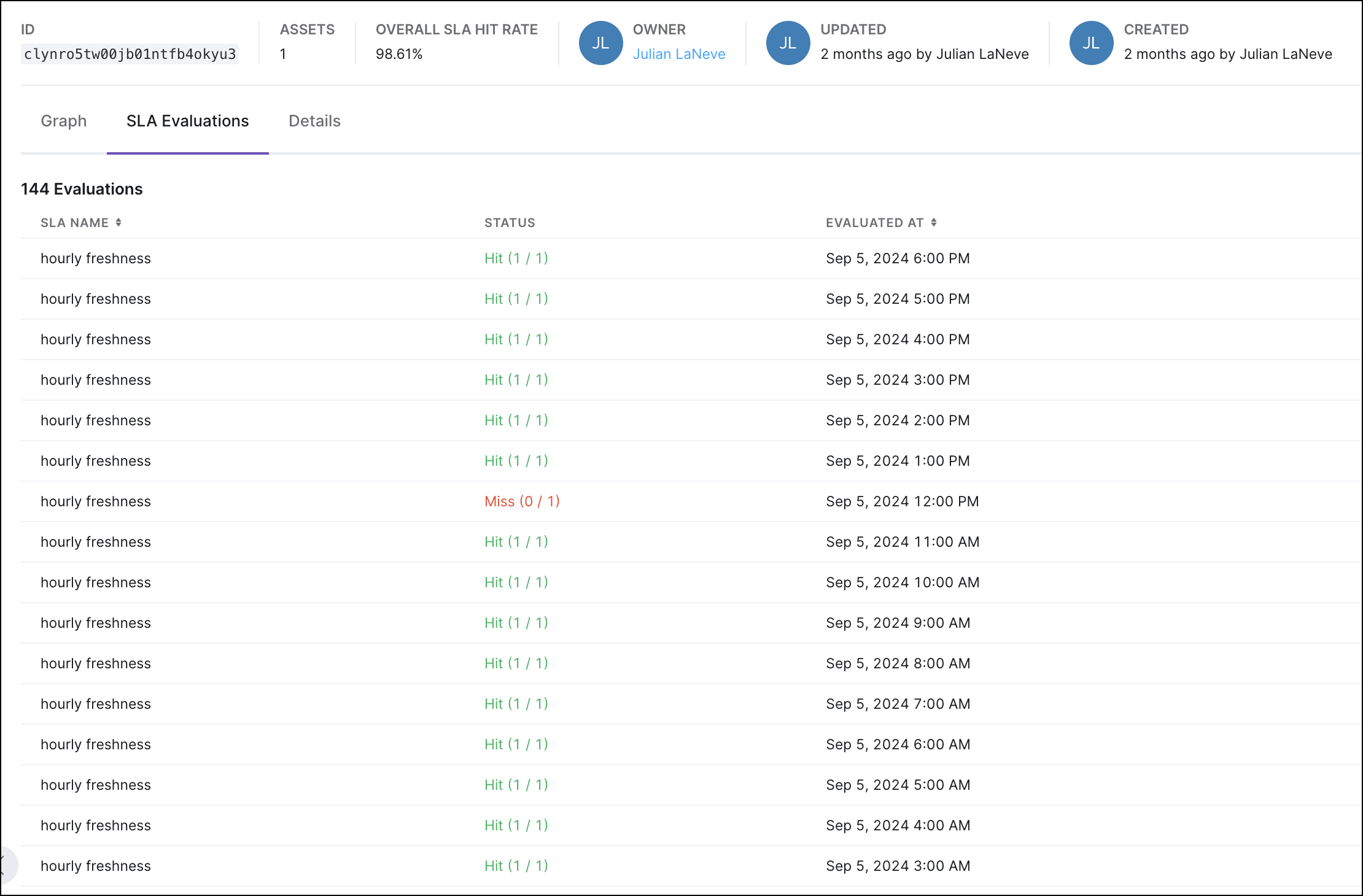
SLA evaluations. You can create custom Service Level Agreements for evaluating the on-time delivery of a data product or its freshness. You can also view all SLAs in effect for the data product along with their current statuses at a glance.
-
Details. You can view assorted metadata including any alerts you have set up for the data product's SLAs on Astro.
To learn more about observability on Astro, including how to leverage data products for performance and health monitoring benefits, see Enhance data observability with Astro.